
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 프롬프트 페르소나
- LLM
- 인공지능
- GPT
- 프롬프트 잘 쓰는법
- mergekit
- TabNet
- 강화학습
- 빅데이터
- ChatGPT
- SOTA
- 비전러닝
- ChatGPT 잘 쓰는 법
- Transformer
- 딥러닝
- 프롬프트
- IT
- chatgpt 꿀팁
- 프롬프트 잘 쓰는 법
- 머신러닝
- 프롬프트 엔지니어링
- AI
- GaN
- 모델링
- 경진대회
- GPT3
- 거대언어모델
- 악성댓글
- LLM 성능 개선
- 컴퓨터 비전
- Today
- Total
빅웨이브에이아이 기술블로그
Neural Prophet, 모델 최적화 본문
시작
안녕하세요! 빅웨이브에이아이 선임 연구원 이우창입니다.
지난번에는 Neural Prophet 모델에 대한 전반적인 내용과 1-step 예측을 소개드렸습니다.
이번에는 기존에 포스팅한 Neural Prophet 모델에서 Multivariate 와 n-step 과정을 함께 사용한
ARX(Auto-Regression X) model과 같은 방법으로 예측 모형을 구축한 후 기존 모델과 비교하여
정확도가 얼마나 개선되었는지 확인 해보고자 합니다.
학습 및 예측하기 위한 예제를 직접 실행해보겠습니다.
소스코드는 아래의 URL을 참조하시면 될 것 같습니다!
https://colab.research.google.com/drive/1BLyPyWe9RMm4v5oy8f_RMXeKKdjl0vb0?usp=sharing
NeuralProphet_Multivariate model 최적화
Colaboratory notebook
colab.research.google.com
패키지 및 데이터 불러오기
<Neural Prophet 설치>
if 'google.colab' in str(get_ipython()):
! pip install git+https://github.com/ourownstory/neural_prophet.git # 코랩 구동 시 패키지 설치
# pip install neuralprophet
# 간단하고 빠르게 설치할 수 있지만, 최신 버전에서의 버그가 발생할 수 있음이전 포스팅에서 다룬 내용과 마찬가지로 코랩에서는 실행마다 세션이 초기화되기 때문에 패키지를 새로 설치해야 합니다.
로컬에서 패키지를 성공적으로 설치하셨다면 스킵해도 되는 부분입니다.
지난 예제에서 설명드렸던 부분은 생략하고 넘어가겠습니다.
<패키지 임포트1>
#패키지 임포트
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
import plotly.express as px
import numpy as np
set_log_level("ERROR")
<패키지 임포트2>
#구글 드라이브 다운로드 패키지
from google_drive_downloader import GoogleDriveDownloader as gdd<데이터 다운로드 및 불러오기>
#데이터 다운로드
gdd.download_file_from_google_drive(file_id='1JRslcolP0XJDQKfXrYl82eyDTCETuzjl',
dest_path='data/energy.zip',
unzip=True)data = pd.read_csv('data/KAG_energydata_complete.csv').fillna(method='ffill').fillna(method='bfill')<데이터 변수 이름 설정>
#시계열 및 종속변수 이름 변경
data = data.rename(columns={"date":"ds","Appliances":"y"})
<데이터 전처리>
#전체 데이터셋 생성
data_pret=pd.concat([data['ds'],X,Y],axis=1)
data_pret=data_pret.reset_index(drop=True)
data_pret생성된 데이터는 시간을 포함하여, X설명변수와 Y예측변수 데이터를 확인할 수 있습니다.
<train, test 분할>
#train test split
cutoff = "2016-05-01" #데이터 분할 기준
train = data[data['ds']<cutoff]
test = data[data['ds']>=cutoff]#최종독립변수 이름 생성
col_lst=data_pret.columns
col_lst=col_lst.drop(['ds','y'])
col_lst=list(col_lst)
col_lstARX model
model에 대해 AR과정 그리고 X독립변수들에 대해서도 변수를 추가 활용하여 시계열 모델을 구축한 뒤, 이전 시간 단계의 데이터들을 모델이 학습하여 다음 시간 단계들에 대한 예측을 위해 사용해볼 것 입니다. 모델 설계를 위해 예측변수인 y데이터와 설명변수인 x데이터들을 2 lag 시킨 데이터를 생성한 후, y를 예측할 수 있도록 데이터를 구성하였습니다.
<모델 설정>
m = NeuralProphet(
growth='off', # 추세 유형 설정(linear, discontinuous, off 중 선택 가능)
yearly_seasonality=False, #년간 계절성 설정
weekly_seasonality=False, #주간 계절성 설정
daily_seasonality=False, #일간 계절성 설정
batch_size=64,#배치 사이즈 설정
epochs=200,#학습 횟수 설정
learning_rate=0.1, # 학습률 설정
n_lags= 2, #lag를 2까지 사용하였으므로, lag를 2로 설정
)
#독립 변인(변수) 추가 및 정규화
m = m.add_lagged_regressor(names=col_lst, normalize="minmax")
#학습 수행
metrics = m.fit(train, freq='h', validation_df=test, progress='plot')
모델 설계에서는 MAE를 최대한 낮출 수 있도록 파라미터를 조정하였으며, ARX모델 설계를 위해
주간, 일간,년 간 계절성에 대한 설정을 배제하였습니다. 또한 추세유형은 off로 설정하였으며,
위의 데이터 전처리에서 수행한 lag를 2만큼 사용하였으므로 n_lags를 2로 설정하였습니다.
여기서 2-step이 아니라, 다른 인수를 원한다면 데이터 전처리 부분부터 원하는 인수만큼 모델에서 lag 시킨 뒤,
모델 학습이 가능합니다. add_lagged_regressor에서는 lag된 X설명변수, lag된 Y예측변수를 모델에서
설명변수로 활용됩니다.
<Metric 확인>
metrics.tail(3)#metric 확인
print("SmoothL1Loss: ", metrics.SmoothL1Loss.tail(1).item())
print("MAE(Train): ", metrics.MAE.tail(1).item())
print("MAE(Test): ", metrics.MAE_val.tail(1).item())
시각화 검증
<Train 및 Test 학습 선 그래프 생성>
#학습 선 그래프 생성
px.line(metrics, y=['MAE', 'MAE_val'], width=800, height=400)

<검증 데이터의 실제값 및 예측값 시각화 비교>
#yhat1과 실제값 시각화(lag 데이터 포함x)
forecast = m.predict(test)
fig = m.plot(forecast[['ds', 'y', 'yhat1']])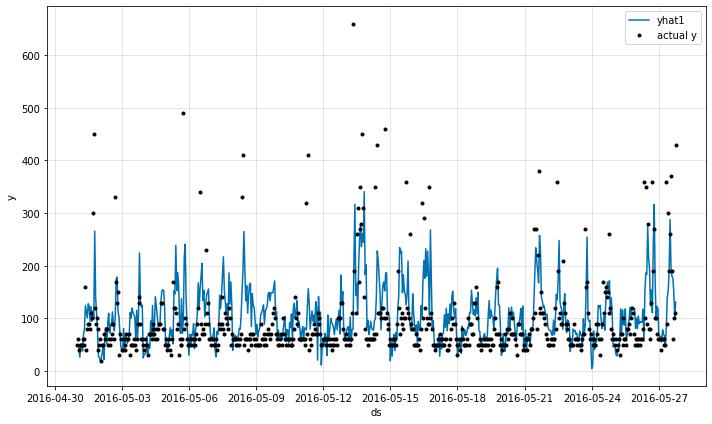
실제값과 예측값을 비교해본 결과, 이상치나 y의 값이 낮은 경우 예측이 잘 되지 않는 모습이 나타나지만 이전의 Multivariate 모델이나, 1-step 과정보다 이상치가 아닌 정상 수치의 y데이터의 추세를 거의 따라가는 모습이 보입니다.
최적화 model : Using Neural Network
이전 단계에서는 은닉층을 사용하지 않았지만 본 파트에서는 은닉층을 사용하여 이전 시간 단계의 데이터를 모델이 학습하여 다음 시간 단계에 대한 예측해보고 검증 데이터와 비교할 것입니다.
m = NeuralProphet(
growth='off', # 추세 유형 설정(linear, discontinuous, off 중 선택 가능)
yearly_seasonality=False, #년간 계절성 설정
weekly_seasonality=False, #주간 계절성 설정
daily_seasonality=False, #일간 계절성 설정
batch_size=64,#배치 사이즈 설정
epochs=100,#학습 횟수 설정
learning_rate=0.1, # 학습률 설정
n_lags= 2, #lag를 2까지 사용하였으므로, lag를 2로 설정
num_hidden_layers=4, #히든 레이어 수 설정
d_hidden=8,#은닉층에 대한 차원 수 설정
)
#독립 변인(변수) 추가 및 정규화
m = m.add_lagged_regressor(names=col_lst, normalize="minmax")
#학습 수행
metrics = m.fit(train, freq='h', validation_df=test, progress='plot')<Metric 확인>
#metric 확인
print("SmoothL1Loss: ", metrics.SmoothL1Loss.tail(1).item())
print("MAE(Train): ", metrics.MAE.tail(1).item())
print("MAE(Test): ", metrics.MAE_val.tail(1).item())
히든 레이어의 추가 후 MAE를 기준으로 성능이 개선됨을 확인할 수 있었습니다.
시각화 검증
<Train 및 Test 학습 선 그래프 생성>
#학습 선 그래프 생성
px.line(metrics, y=['MAE', 'MAE_val'], width=800, height=400)
<실제값 및 예측값 비교(검증 데이터)>
#yhat1과 실제값 시각화(lag 데이터 포함x)
forecast = m.predict(test)
fig = m.plot(forecast[['ds', 'y', 'yhat1']])
#끝부분만 자세히 보기
fig_prediction = m.plot(forecast[-48:])
Multivariate model과 ARX model의 정확도 비교

은닉층을 고려한 ARX model은 기존 Multivariate model과 비교하였을 때 훈련 및 검증 데이터상에서의 MAE 값이 훨씬 개선되었음을 알 수 있었습니다.
이번 포스트에서는 Neural Prophet모델의 하이퍼 파리미터를 수정하여 최적의 모델을 구축해보는 과정을 수행하였습니다. 최적화 단계는 본 포스트와 같이 lag를 2단계 뿐만 아니라, 좀 더 고려할 수 도 있을 것이고 여러가지 경우의 수를 따져가며 MAE가 최소화 되는 방향을 고려해보면 좀 더 좋은 결과를 얻을 수 있을 것이라 기대됩니다.
읽어 주셔서 감사합니다!
'Python 코드 예제' 카테고리의 다른 글
| Neural Prophet, 1-step model 예제 (2) | 2022.05.02 |
|---|---|
| Neural Prophet, Multivariate 예제 (9) | 2022.03.17 |
| (Python code) 딥러닝 기술을 활용한 악성 댓글 분류 (2) | 2021.03.09 |


