
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- ChatGPT 잘 쓰는 법
- 비전러닝
- 프롬프트 페르소나
- TabNet
- GPT3
- chatgpt 꿀팁
- 딥러닝
- AI
- SOTA
- 악성댓글
- 인공지능
- GaN
- ChatGPT
- LLM 성능 개선
- Transformer
- 컴퓨터 비전
- 경진대회
- mergekit
- LLM
- 프롬프트
- 머신러닝
- GPT
- IT
- 프롬프트 잘 쓰는법
- 빅데이터
- 프롬프트 엔지니어링
- 프롬프트 잘 쓰는 법
- 거대언어모델
- 모델링
- 강화학습
- Today
- Total
빅웨이브에이아이 기술블로그
(Python code) 딥러닝 기술을 활용한 악성 댓글 분류 본문
코드 예제
지난 포스트에서 다뤘던 딥러닝 기반 악성 댓글 분류 모델링을 실제 python code 예제를 실행 해보겠습니다.
import pandas as pd
import re
import konlpy
from konlpy.tag import Okt
from tensorflow.keras.callbacks import ModelCheckpoint
import sklearn
import multiprocessing
okt = Okt()
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import os
필요한 모듈을 불러옵니다. Konlpy 패키지는 자바 설정을 해주셔야 하니 따로 설치해주세요.
#CSV 데이터 read
toxic = pd.read_csv('.../data/toxic_sample.csv')
#순수 한글 추출 함수
def test(s):
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('', s)
return result
#pandas series에 함수 적용
toxic['Toxic Comment']= toxic['Toxic Comment'].apply(str)
toxic['Toxic Comment'] = toxic.apply(lambda row: test(row['Toxic Comment']), axis=1)데이터를 불러오고 특수 문자를 간단한 함수를 활용하여 제거합니다.
#konlpy tokenizing
toxic['token'] = toxic.apply(lambda row: okt.morphs(row['Toxic Comment'], stem = True, norm = True), axis=1)
#column 정리
toxic = toxic[['token', '악성댓글']]텍스트 데이터를 수치화하기 위해서 Konlpy 토크나이징을 수행합니다.
okt라는 패키지의 morphs, 즉 형태소 단위로 토크나이징을 할 수 있는 패키지를 활용했습니다. 이전 twitter 패키지로 유명했었죠. 이름이 바뀌었습니다.
okt.morphs의 기능 중 stem과 norm이 있는데, stem이란 다양한 형태로 표현되는 단어들을 하나로 통일하고, norm의 경우 정규화 기능을 통해 혼재된 한글 단어 표현들을 묶어줍니다.
#모듈 임포트
import sklearn.model_selection
from tensorflow.keras.preprocessing.text import Tokenizer
#시드 설정
np.random.seed(777)
#케라스 토크나이저 사용
tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
tokenizer.fit_on_texts(toxic['token'])
#train, validation, test 데이터 분할, 7:1:2
train, val, test = np.split(toxic.sample(frac=1), [int(.6*len(toxic)), int(.8*len(toxic))])
#train 데이터 벡터 행렬화
sequences = tokenizer.texts_to_sequences(train['token'])
x_train = keras.preprocessing.sequence.pad_sequences(sequences, maxlen = maxlen)
sequences = tokenizer.texts_to_sequences(val['token'])
x_val = keras.preprocessing.sequence.pad_sequences(sequences, maxlen = maxlen)
sequences = tokenizer.texts_to_sequences(test['token'])
x_test = keras.preprocessing.sequence.pad_sequences(sequences, maxlen = maxlen)모델 학습을 위해 데이터를 train, validation, test로 구분합니다.
단어에 임의의 숫자를 부여하고, 딥러닝 모델에 임베딩할 수 있도록 변환합니다.
x_train
데이터를 확인했을 때 행렬의 오른쪽 부분에 채워지는 형식으로 구성되는 것을 볼 수 있습니다.
가장 기본적인 워드 임베딩 방식입니다.
다른 사전 학습 워드 임베딩 기법은 추후에 포스팅하도록 하겠습니다.
y_train = pd.get_dummies(train['악성댓글'].apply(str)).values
y_val = pd.get_dummies(val['악성댓글'].apply(str)).values
y_test = pd.get_dummies(test['악성댓글'].apply(str)).values분류를 할 수 있도록 출력 데이터들을 dummy 형태로 변환합니다.
#텍스트 데이터에 포함된 총 단어 수를 지정
words_count = len(tokenizer.word_counts)
#임베딩 차원 수 125
embed_dim = 125
#임베딩 입력 변수 지정
inputs = tf.keras.layers.Input(shape = (maxlen, ))
emb = tf.keras.layers.Embedding(words_count+1, embed_dim)(inputs)
emb = tf.keras.layers.Reshape((maxlen, embed_dim, 1))(emb)
#Highway Network 입력 연결
random_layer = layers.Embedding(words_count+1, embed_dim, mask_zero=True, trainable = True)
x1 = random_layer(inputs)총 단어 수(words_count) 변수를 딥러닝 모델의 입력으로 설정한 후 reshape를 통해 행렬 차원을 재조정합니다.
highway network를 활용하기 위해 입력 변수를 reshape하지 않고 임베딩하여 random_layer의 변수로 지정합니다.
#Conv 레이어 설정
cnn1 = layers.Conv2D(activation= 'relu',filters=25, kernel_size=(1,embed_dim), strides=(1,1))(emb)
#Maxpooling
cnn1_pool = layers.MaxPool2D(strides=(1,1), pool_size=(maxlen,1))(cnn1)
#Activation Map Flatten
cnn1_pool = layers.Flatten()(cnn1_pool)
cnn2 = layers.Conv2D(activation= 'relu',filters=25, kernel_size=(2,embed_dim), strides=(1,1))(emb)
cnn2_pool = layers.MaxPool2D(strides=(1,1), pool_size=(maxlen-1,1))(cnn2)
cnn2_pool = layers.Flatten()(cnn2_pool)
cnn3 = layers.Conv2D(activation= 'relu',filters=25, kernel_size=(3,embed_dim), strides=(1,1))(emb)
cnn3_pool = layers.MaxPool2D(strides=(1,1), pool_size=(maxlen-2,1))(cnn3)
cnn3_pool = layers.Flatten()(cnn3_pool)
cnn4 = layers.Conv2D(activation= 'relu',filters=25, kernel_size=(4,embed_dim), strides=(1,1))(emb)
cnn4_pool = layers.MaxPool2D(strides=(1,1), pool_size=(maxlen-3,1))(cnn4)
cnn4_pool = layers.Flatten()(cnn4_pool)
cnn5 = layers.Conv2D(activation= 'relu',filters=25, kernel_size=(5,embed_dim), strides=(1,1))(emb)
cnn5_pool = layers.MaxPool2D(strides=(1,1), pool_size=(maxlen-4,1))(cnn5)
cnn5_pool = layers.Flatten()(cnn5_pool)
#통합
cnn_concated = layers.concatenate([cnn1_pool,cnn2_pool,cnn3_pool, cnn4_pool, cnn5_pool])cnn1~5의 레이어는 각각 1~5 글자를 n-gram 형식으로 인식하면서 학습합니다.
각 레이어는 maxpooling 후 activation map이 flatten되는 형태로 통합(concate)됩니다.
# 1차원 형태로 global average pooling
gap = layers.GlobalAvgPool1D()(x1)
#변환 게이트 레이어
trans = layers.Dense(embed_dim, activation="sigmoid", use_bias=True)(cnn_concated)
#통과 게이트 레이어
carry = 1 - trans
#변환 게이트는 모델의 학습 결과를 예측에 활용
gap = layers.Multiply()([trans,gap])
#통과 게이트는 모델의 학습을 거치지 않고 그대로 결과 값에 반영됨
concated = layers.Multiply()([carry, cnn_concated])
#전체 레이어 통합
concated = layers.Add()([concated, gap])
#dropout
dr = layers.Dropout(0.1)(concated)
#예측 결과 값 출력
outputs = layers.Dense(2, activation="sigmoid")(dr)하이웨이 네트워크 적용 및 모델링 통합 과정입니다.
과적합을 방지하기 위해 입력 값의 신호를 그대로 전달할 수 있는 경로를 연결하는 방식입니다.
#레이어 모델 정의
model = keras.Model(inputs=inputs, outputs=outputs)
#optimizers 모듈 임포트
from keras import optimizers
#adam optimizer default 값
adam = keras.optimizers.Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)모델 정의 및 epoch 최적화를 위한 adam optimizer를 사용합니다.
현재는 default 값으로 설정되어 있으나 하이퍼 파라미터를 변경 시 모델의 성능에 영향을 줄 수 있습니다.
#모델 체크포인트 저장 코드
callbacks = ModelCheckpoint("model/kim_CNN.h5", monitor='val_loss', mode = 'auto', verbose=1, save_best_only=True, save_weights_only=True)
#모델 컴파일
model.compile(loss = "binary_crossentropy", optimizer = adam, metrics=["accuracy"])
#모델 학습
model.fit(
x_train, y_train,
batch_size=32, epochs=20,
validation_data=(x_val, y_val),
callbacks= [callbacks]
)여러 epoch 수행 중 가장 최고의 모델을 저장하기 위해 callback 변수를 정의합니다.
"val_loss"가 가장 낮은 지점에서 모델이 저장됩니다.

#모델 가중치 로딩
model.load_weights("model/kim_CNN.h5")
#테스트 데이터로 모델 예측
m_pred = model.predict(x_test)
#데이터 형식 통일
pred = np.argmax(m_pred, axis=1)
#데이터 형식 통일
true = np.argmax(y_test, axis=1)
#최종 딥러닝 모델 검증 결과 출력
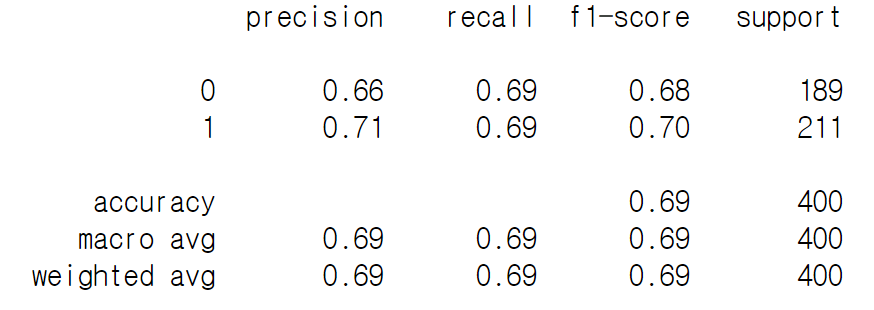
print(sklearn.metrics.classification_report(true, pred)) 최종적으로 test 데이터의 결과를 가지고 모델의 성능을 평가했습니다.
f1 score 69% 수준으로 양호한 성능이 측정됩니다.
예제의 기본 모델 구조에 하이웨이 네트워크, OOV 처리, 워드 임베딩 등의 추가 분석을 한다면 더욱 정밀한 분석이 가능할 것입니다.
하이웨이 네트워크의 경우 데이터의 양이 많지 않고 모델링이 크게 복잡하지 않기 때문에 큰 효과를 보이지는 못하는 것으로 나타납니다.
OOV 처리의 경우 외부 데이터를 사용하지 않는 경진대회 환경에서 모델의 성능을 높이기 위해 word2vec을 활용한 것으로 사전학습된 워드 임베딩 모델을 활용하면 모델의 성능을 더욱 높일 수 있습니다.
'Python 코드 예제' 카테고리의 다른 글
| Neural Prophet, 모델 최적화 (9) | 2022.05.09 |
|---|---|
| Neural Prophet, 1-step model 예제 (2) | 2022.05.02 |
| Neural Prophet, Multivariate 예제 (9) | 2022.03.17 |


