
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- chatgpt 꿀팁
- GaN
- 프롬프트 잘 쓰는법
- 모델링
- 프롬프트 잘 쓰는 법
- 거대언어모델
- 비전러닝
- GPT
- LLM 성능 개선
- 악성댓글
- ChatGPT 잘 쓰는 법
- Transformer
- 인공지능
- GPT3
- 프롬프트
- 컴퓨터 비전
- TabNet
- SOTA
- 경진대회
- 딥러닝
- 빅데이터
- mergekit
- 강화학습
- 프롬프트 엔지니어링
- LLM
- 머신러닝
- ChatGPT
- 프롬프트 페르소나
- AI
- IT
- Today
- Total
빅웨이브에이아이 기술블로그
Neural Prophet, Multivariate 예제 본문
시작
안녕하세요! 빅웨이브에이아이 선임 연구원 이현상입니다.
지난번에는 페이스북(현 메타)의 Neural Prophet의 간단한 개념과 베이스라인 코드를 소개드렸습니다.
간단하게 단변량 학습으로 1시점 뒤의 값을 예측하는 코드였습니다.
이번에는 Neural Prophet으로 다변량(Multivariate) 학습 및 다시점 예측 예제를 직접 실행해보겠습니다!
소스코드는 아래의 URL을 참조하시면 됩니다!
https://colab.research.google.com/drive/13B0TyasngCzZAVP1vVIvfZusYwVUPJGx?usp=sharing
NeuralProphet_Multivariate.ipynb
Colaboratory notebook
colab.research.google.com

패키지 및 데이터 임포트
<Neural Prophet 설치>
! pip install neuralprophet코랩에서는 실행마다 세션이 초기화되기 때문에 패키지를 새로 설치해야 합니다.
로컬에서 패키지를 성공적으로 설치하셨다면 스킵해도 되는 부분입니다.
지난 예제에서 설명드렸던 부분은 생략하고 넘어가겠습니다.
<패키지 임포트1>
#패키지 임포트
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
import plotly.express as px
set_log_level("ERROR")
<패키지 임포트2>
#구글 드라이브 다운로드 패키지
from google_drive_downloader import GoogleDriveDownloader as gdd필요한 패키지를 임포트합니다.
<구글 드라이브 데이터 다운로드>
#데이터 다운로드
gdd.download_file_from_google_drive(file_id='1JRslcolP0XJDQKfXrYl82eyDTCETuzjl',
dest_path='data/energy.zip',
unzip=True)지난 베이스라인 예제와 같은 데이터를 다운로드 합니다.
<데이터 임포트>
data = pd.read_csv('data/KAG_energydata_complete.csv').fillna(method='ffill').fillna(method='bfill')
데이터 전처리 및 모델학습
<독립변수 칼럼 선택(다변량)>
#독립변수 정의
col_lst = ['lights', 'T1', 'RH_1', 'T2', 'RH_2', 'T3',
'RH_3', 'T4', 'RH_4', 'T5', 'RH_5', 'T6', 'RH_6', 'T7', 'RH_7', 'T8',
'RH_8', 'T9', 'RH_9', 'T_out', 'Press_mm_hg', 'RH_out', 'Windspeed',
'Visibility', 'Tdewpoint', 'rv1', 'rv2']여기서 부터 베이스라인 코드와 다른 부분들이 등장하는데요,
다변량 변수를 활용하기 위해 미리 독립변수 칼럼을 지정합니다.
<데이터 변수 이름 설정>
#시계열 및 종속변수 이름 변경
data = data.rename(columns={"date":"ds","Appliances":"y"})시간변수 및 종속변수(예측변수)의 칼럼명을 맞춰줍니다.
<train, test 분할>
#train test split
cutoff = "2016-05-01" #데이터 분할 기준
train = data[data['ds']<cutoff]
test = data[data['ds']>=cutoff]
<모델 설정>
m = NeuralProphet(
n_forecasts=48, #8시간 예측
n_lags = 6, #1시간 뒤 regressor 지연 반영
weekly_seasonality=3, #주간 계절성 설정
daily_seasonality=5, #일간 계절성 설정
d_hidden=128, #은닉층 뉴런 설정
learning_rate=0.01, #학습률 설정
batch_size=128, #배치 사이즈 설정
epochs=200, #학습 횟수
)
#독립 변인(변수) 추가 및 정규화
m = m.add_lagged_regressor(names=col_lst, normalize="minmax")
#학습 수행
metrics = m.fit(train, freq='h', validation_df=test, progress='plot')모델링 부분에서 MAE를 최대한 낮출 수 있도록 파라미터를 조정했습니다.n_forecasts를 설정안하고 모델을 학습하면 단순하게 다음 timestep(10분)을 예측합니다.일반적인 문제와 맞게 480분, 즉 8시간을 예측하는 설정을 n_forecasts=48로 설정했습니다.n_lags는 트렌드 예측에서 지연을 주는 것으로, 현재의 변수가 얼마 뒤의 예측변수에 영향을 미칠 지 설정합니다.즉, n_lags를 6으로 설정하면 현재의 변수들이 60분 뒤의 에너지 사용량을 예측하는데 적용됩니다.add_lagged_regressor를 추가함으로써 다변량을 모델에 입력합니다.
<Metric 확인>
metrics.tail(3)Neural Prophet의 모델 변수는 pandas 형태로 성능 지표를 확인할 수 있도록 지원합니다.아주 간편하죠?
<주요 성능 지표 확인>
#metric 확인
print("SmoothL1Loss: ", metrics.SmoothL1Loss.tail(1).item())
print("MAE(Train): ", metrics.MAE.tail(1).item())
print("MAE(Test): ", metrics.MAE_val.tail(1).item())
마지막 학습 단계에서 Loss, MAE(Train), MAE(Test)를 확인합니다.따로 Metric 함수를 구성할 필요가 없습니다.이전 베이스라인에서 MAE를 생각하면 큰 성능의 개선이 있다고 볼 수 있습니다.
<MAE 추이 확인 시각화>
#학습 선 그래프 생성
px.line(metrics, y=['MAE', 'MAE_val'], width=800, height=400)
학습이 잘되었는지 plotly 그래프로 간단하게 나타냈습니다.
여러번 테스트해본 결과 epoch 수를 충분히 수행해야 모델 최적화가 이루어지는 것을 확인했습니다.
시각화 검증
<실제값 예측값 시각화>
#yhat1과 실제값 시각화
forecast = m.predict(test)
fig = m.plot(forecast[['ds', 'y', 'yhat1']])
yhat 1을 확인했을 때 이상치의 움직임도 나름 모델이 포착하려는 모습이 보입니다.forecast 변수를 그대로 입력할 경우 yhat10까지 시각화가 이루어지는데 제대로 확인이 어려워서 yhat1만 지정했습니다.따로 yhat48(48번째 예측값의 모음)을 시각화하려 했으나 자체 plot 기능에서는 구현하지 못했습니다.커스텀 시각화 코드가 필요한 것으로 판단됩니다.
<3일간 예측 결과 확인>
forecast = m.predict(test)
m = m.highlight_nth_step_ahead_of_each_forecast(1)
fig = m.plot(forecast[-3*24:]) #3일간 데이터 확인
테스트 데이터에서 마지막 3일간의 예측 및 실제값을 나타냅니다. 특출나게 정확하지는 않지만 어느정도의 트렌드는 따라가는 것을 확인할 수 있습니다.
<예측 변인 파라미터 확인>
fig_param = m.plot_parameters()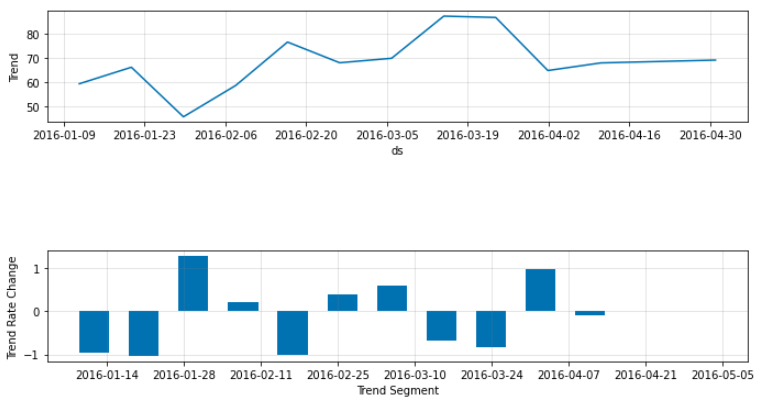
마무리
이번 포스트에서는 Neural Prophet을 활용하여 다변량 예측을 수행했습니다.
제대로 모델을 검증하는 코드가 추가적으로 필요하지만, 대략적인 분석을 이러한 방식으로 수행할 수 있습니다.
실제로 시계열 데이터를 분석하기 위해서는 forecasting step, window size, array dimension 등 다양한 요소를 고려해야하기 때문에 복잡한 부분이 있습니다.
이에 Pytorch에서는 자체 TimeseriesDataset 변환 기능을 지원하며, Neural Prophet에서는 더욱 간단한 프로세스를 지원합니다.
향후 포스트에서는 고정 변수 및 미래에 이미 알 수 있는 변수들을 모델에 입력하는 코드를 소개드리겠습니다.
읽어주셔서 감사합니다!
'Python 코드 예제' 카테고리의 다른 글
| Neural Prophet, 모델 최적화 (9) | 2022.05.09 |
|---|---|
| Neural Prophet, 1-step model 예제 (2) | 2022.05.02 |
| (Python code) 딥러닝 기술을 활용한 악성 댓글 분류 (2) | 2021.03.09 |


