
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 프롬프트 잘 쓰는 법
- IT
- ChatGPT
- 컴퓨터 비전
- 머신러닝
- 프롬프트 엔지니어링
- 프롬프트 페르소나
- 비전러닝
- 모델링
- 프롬프트
- SOTA
- 프롬프트 잘 쓰는법
- 인공지능
- 악성댓글
- LLM
- TabNet
- 딥러닝
- mergekit
- 빅데이터
- AI
- 거대언어모델
- GPT
- 경진대회
- GaN
- GPT3
- Transformer
- ChatGPT 잘 쓰는 법
- LLM 성능 개선
- 강화학습
- chatgpt 꿀팁
- Today
- Total
빅웨이브에이아이 기술블로그
이미지 생성 AI, 어디까지 가능할까? 본문
<ChatGPT를 활용하여 작성한 블로그입니다. 블로그 작성기>
시작
현재 인공지능 기술은 놀라운 발전을 이루고 있습니다.
이 중에서도 최근에 등장한 텍스트-이미지 생성 AI인 Dalle2, Stable Diffusion2, 그리고 영상 생성 AI인 Gen-1은 많은 이들의 관심을 받고 있습니다.
Dalle2는 텍스트를 입력하면 해당 텍스트에 대응하는 이미지를 생성하는 기술로, 이전 모델 대비 훨씬 더 자연스러운 이미지 생성이 가능해졌습니다.
Stable Diffusion2는 이미지 생성 과정에서 불안정한 요소들을 안정적으로 다루는 기술로, 높은 해상도와 질의 이미지 생성이 가능해졌습니다.
마지막으로, Gen-1은 다양한 주제와 스타일의 영상을 생성하는 기술로, 상당한 수준의 창의적인 결과물을 도출합니다.
이처럼 최근 발표된 이 기술들은 이미지와 영상 생성 분야에서 놀라운 가능성을 제시하며, 우리의 상상력을 더욱 확장시켜줍니다.
오늘의 포스트에서는 텍스트-비전 분야의 Dalle2, Stable Diffusion2, Gen-1 기술들을 소개하고,
신기한 그 예시들도 같이 보여드리겠습니다.
Dalle2
Dalle2는 OpenAI에서 2022년 4월 6일 발표한 텍스트-이미지 생성 AI 모델로, 기존 모델 대비 17% 이상의 성능 향상을 보입니다.
이러한 향상은 Dalle2가 기존 모델에서 사용되던 트랜스포머(transformer) 구조를 사용하면서도 더욱 복잡한 시각-언어 상호작용을 처리할 수 있는 능력을 보인 데 기인합니다.
Dalle2는 이미지 생성에 필요한 정보를 텍스트 입력으로 받아들이며, 이를 기반으로 이미지를 생성합니다.
이를 위해 Dalle2는 CLIP(Contrastive Language-Image Pre-Training)라는 이미지-텍스트 사전학습 임베딩 대조모델을 사용합니다.
CLIP 모델은 대규모 데이터를 사용하여 이미지와 텍스트 간의 상호작용 패턴을 학습한 후, 이를 임베딩으로 변환합니다.
Dalle2는 이러한 CLIP 임베딩을 사용하여 이미지 생성 과정에서 더욱 세밀한 상호작용을 수행합니다.
또한, Dalle2는 이미지 생성의 불안정한 요소를 안정적으로 다룰 수 있는 확산(diffusion) 모델을 사용합니다.
Dalle2는 이러한 다양한 기술들을 결합하여, 이전 모델보다 더욱 자연스러운 이미지 생성이 가능해졌습니다.
더불어, Dalle2는 적은 양의 데이터로도 이미지 생성을 수행할 수 있어, 기업들이나 개인 사용자들에게도 매우 유용한 기술입니다.
그럼 이제 Dalle2의 예시를 보여드리겠습니다.
확산(Diffusion) 모델을 기반으로 다양한 스타일의 그림을 생성하면서 본인만의 인물 초상화를 그렸습니다!
그림에 대한 배경 지식만 어느 정도 갖춘다면 일반인 수준 이상의 작품을 충분히 만들수 있을 것 같네요.
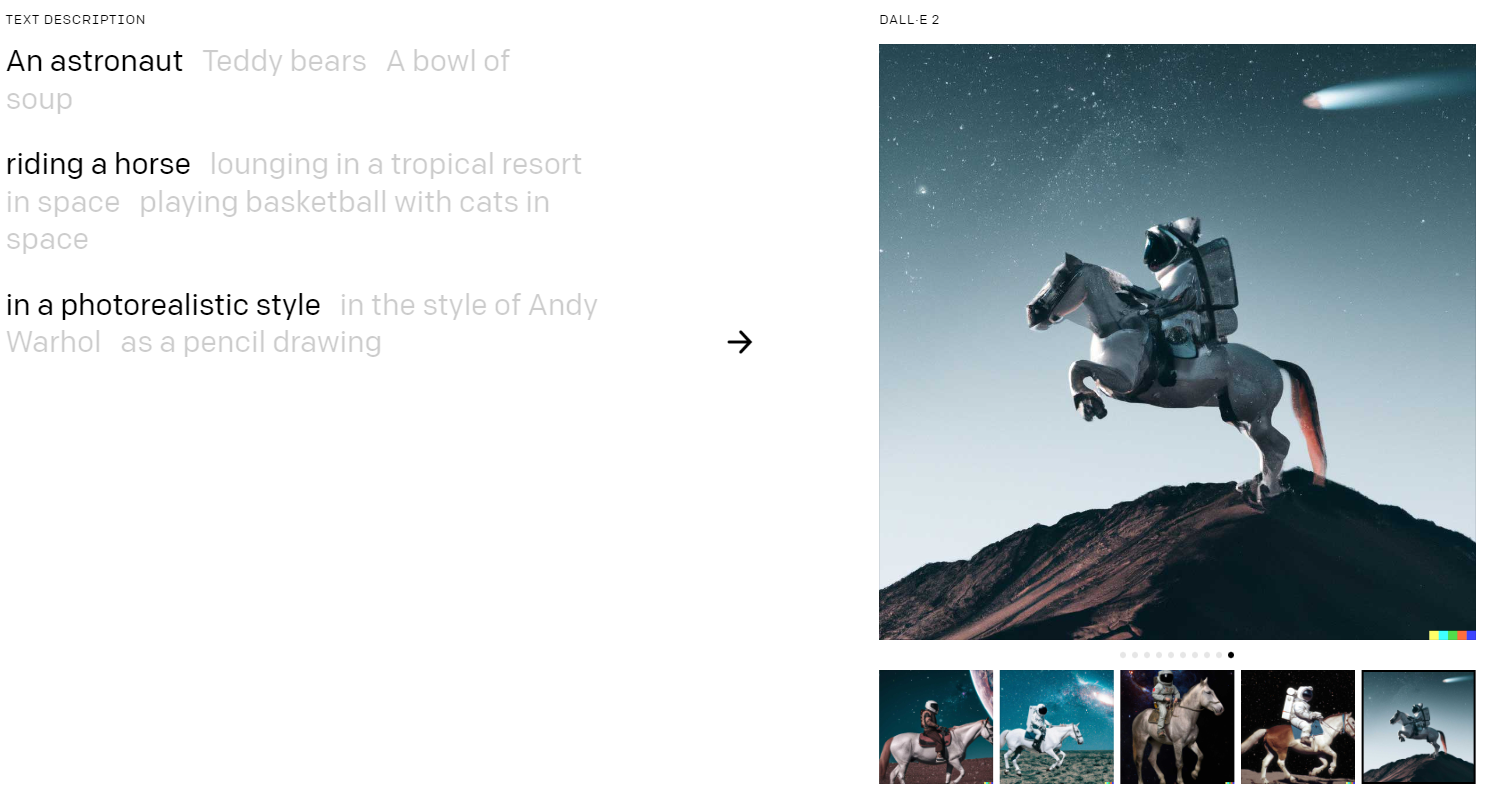
An astronaut riding a horse in a photorealistic style(실사와 같은 스타일로 말을 타고 있는 우주 비행사)라고 입력했을 때 DALLE2의 예시입니다.
DALLE2 홈페이지에 가면 더 많은 예시들을 보실 수 있습니다.
좌측 상단에 문구를 클릭하면 내용에 따라서 그림 예시를 보여주고, 우측 하단의 기타 이미지들은 확산 모델로 생성된 다양한 그림들입니다.
하나의 주제에 대해서도 다양한 표현이 가능합니다.
위의 우주 비행사 예시를 앤디 워홀 스타일로 바꿔보겠습니다.

Stable Diffusion 2
최근 NovelAI의 일러스트 생성 서비스로 유명해진 Stable Diffusion2에 대해서 소개드리겠습니다.
Stable Diffusion2는 Stability AI에서 개발한 텍스트-이미지 잠재 확산 모델입니다.
이 모델은 이전 모델 대비 768x768 해상도를 지원하며, x4 업스케일링 기능을 추가하여 높은 해상도 이미지 생성을 가능하게 합니다.
또한, OpenCLIP-ViT/H를 Fine-tuning에 적용하여 더욱 정교한 이미지 생성이 가능합니다.
이 모델은 안정적인 확산 방식을 사용하여 이미지 생성 과정에서 발생할 수 있는 노이즈와 왜곡을 최소화하며, 높은 품질의 이미지 생성을 지원합니다.
Stable Diffusion1 버전에서 발전한 그 예시를 보여드리겠습니다.


위의 예시는 Stable Diffusion 2의 공식 Github에서 가져온 것입니다.
확실히 해상도나 세부 디테일 표현에서 이전 버전보다 성능이 좋아진 것을 확인할 수 있군요.

이번 버전에서 또 재밌게 봤던 것은 바로 이 x4 업스케일링 부분입니다!
위의 예시에서 확실하게 우측 이미지가 해상도가 선명해진 것을 확인할 수 있습니다.
특히 강아지의 눈 쪽의 표현에서 아주 자연스러움이 느껴지네요.
Stable Diffusion에서 제공하는 x4 업스케일링 기능은 저해상도 이미지를 가로 세로 너비 각각 2배 늘려준다고 생각하시면 됩니다.
즉, 256x256 사이즈의 이미지를 512x512까지 자연스럽게 합성이 가능하다는 것이죠.
이제 이 Stable Diffusion 기술에서 발전한 Gen-1에 대해서 알아보겠습니다.
Gen-1
Gen-1은 Stable Diffusion을 개발한 Stability AI에서 나온 스타트업 "Runway"가 개발한 기술입니다.
이 모델은 기계학습과 딥러닝 기술을 이용하여, 텍스트 설명과 단일 이미지를 바탕으로 3D 비디오를 생성하는 모델입니다.
Gen-1은 먼저 이미지의 깊이 정보를 추정하기 위해 "monocular depth estimates"라는 기술을 사용합니다.
이를 통해 이미지에서 물체의 깊이를 추정한 후, depth map을 Gen-1 모델의 인풋으로 활용합니다.
이후에는 텍스트 설명과 이미지에서 얻은 3D 공간 정보를 이용하여, 비디오 생성을 위한 렌더링을 수행합니다.
이를 통해 높은 해상도와 고화질의 3D 비디오를 생성할 수 있습니다.
또한, 이 모델은 확산 모델로서 작동하며, 생성된 비디오를 다시 입력으로 사용하여 더 많은 비디오를 생성하는 것이 가능합니다.
이제 Gen-1의 예시를 같이 살펴보겠습니다.
Gen-1 위의 영상에서 춤추는 사람이 중간의 이미지의 노이즈에 따라서 아래의 영상을 생성했습니다!
기존의 이미지 생성 AI 기반 영상들은 생성의 불확실성 때문에 확실히 부자연스러운 영역이 있었는데,
Gen-1은 확실하게 일관성 있는 영상의 시퀀스를 보여줍니다.
다른 예시들도 매우 대단한 퀄리티의 영상을 보여줍니다.
마무리
이번 포스트에서는 이미지 및 영상 생성 AI에 대해서 소개드렸습니다.
이미지 생성, 즉 그림의 예술 분야는 AI를 적용하기 어렵다고 생각했는데,
이제는 이미지 퀄리티가 아주 높은 수준으로 올라왔고, 비디오 생성 역시도 첫 프로토타입 모델의 수준에서 아주 자연스러운 품질을 보여줍니다.
2020년부터 이미지 부터 영상, 텍스트 등의 생성 AI들이 개발되면서 산업계에도 큰 변화의 바람이 불고 있습니다.
이제는 생성 AI 간의 결합을 통한 시너지, 더 나아가서 범용 AI를 연구하고자 하는 방향성도
마냥 꿈같은 얘기는 아닌 것 같네요.
긴 글 읽어주셔서 감사합니다!
'기술 블로그' 카테고리의 다른 글
| LangChain: LLM 서비스를 어떻게 개발할 수 있을까? (62) | 2024.01.24 |
|---|---|
| AI로 블로그 쓰기 - ChatGPT를 가장 쉽게 활용하는 방법 (4) | 2023.02.24 |
| AI가 블로그를 대신 써준다고? 텍스트 생성 AI로 기술 블로그 써보기 (0) | 2023.02.02 |
| SAINT, 정형데이터 분석을 위한 최첨단 딥러닝! (0) | 2022.08.04 |
| SOTA 알고리즘 리뷰 7 - DINO (3) | 2022.05.31 |



