
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- IT
- ChatGPT 잘 쓰는 법
- 딥러닝
- 빅데이터
- 거대언어모델
- 프롬프트 잘 쓰는 법
- ChatGPT
- TabNet
- 경진대회
- GPT3
- Transformer
- 악성댓글
- 프롬프트 잘 쓰는법
- 프롬프트
- 비전러닝
- 프롬프트 페르소나
- 컴퓨터 비전
- 머신러닝
- 프롬프트 엔지니어링
- LLM
- 강화학습
- 모델링
- GPT
- GaN
- SOTA
- chatgpt 꿀팁
- LLM 성능 개선
- AI
- mergekit
- Today
- Total
빅웨이브에이아이 기술블로그
SOTA 알고리즘 리뷰 7 - DINO 본문
시작
안녕하십니까? 빅웨이브에이아이 선임 연구원 이현상입니다.
지난 Neural Prophet 리뷰 이후 오랜만에 SOTA 알고리즘에 대해서 소개드리게 되었습니다!
오늘의 SOTA 알고리즘은 바로 DINO(DETR with Improved deNoising anchOr boxes)로 현재 COCO 2017 객체 탐지 데이터셋에서 1위를 차지하고 있습니다.
풀네임에서 따온 이름이 다소 억지스럽긴 하지만, 최근 논문에서는 단어의 느낌을 위해서 이런 방식을 사용하기도 하더라구요.
그러나! 다소 급조한 듯한 이름과는 다르게 DINO는 객체 탐지 분야의 타 알고리즘과 비교했을 때 아주 혁신적인 실험 결과를 발표했습니다.
그 내용에 대해서 핵심 아이디어 및 모델 아키텍처를 소개드리겠습니다.
Key Idea
DINO의 Key Idea는 크게 3가지로 정리됩니다.
바로 CDN, Mixed Query Selection, Look Forward Twice 기법 인데요, 하나씩 살펴보겠습니다.
CDN
DETR은 앵커에 객체가 없을 때 Negative로 분류하는 것에 아주 취약하며, 객체가 겹쳐있을 때 이를 인지하기 어렵습니다.
이는 모델 성능에 큰 악영향을 미치며 실제 비전 시스템상에서도 큰 문제점이 될 수 있습니다.
DINO에서는 CDN(Constrative DeNoising) 기법을 활용하여 이 문제를 보완했습니다.
CDN이란 Positive Query와 Negative Query를 생성하여 디코더에 입력하는 기법입니다.
Positive Query라는 것은 객체의 실제 Ground Truth Bbox가 포함된 이미지 영역을 의미하며, Negative Query는 그 외의 배경 영역을 의미합니다.
객체가 n개일 경우, 2*n개의 Noise 쿼리(샘플)을 생성하는데, 이 과정에서 객체가 겹치는 상황에 대처가 가능해집니다.
Positive 및 Negative Query는 λ(람다)라는 하이퍼 파라미터에 의해서 크기가 결정됩니다.
Positive Query에는 GIOU Loss가 적용되고, Negative Query에서는 Focal Loss가 적용됩니다.
즉, CDN 디코더에서는 Noise 샘플 쿼리에 대한 객체 존재 여부를 분류하고, bbox 중심 좌표를 다시 예측하면서 Denoising을 수행합니다.
이를 통해 모델의 앵커 박스에 대한 예측값을 개선합니다.

Mixed Query Selection
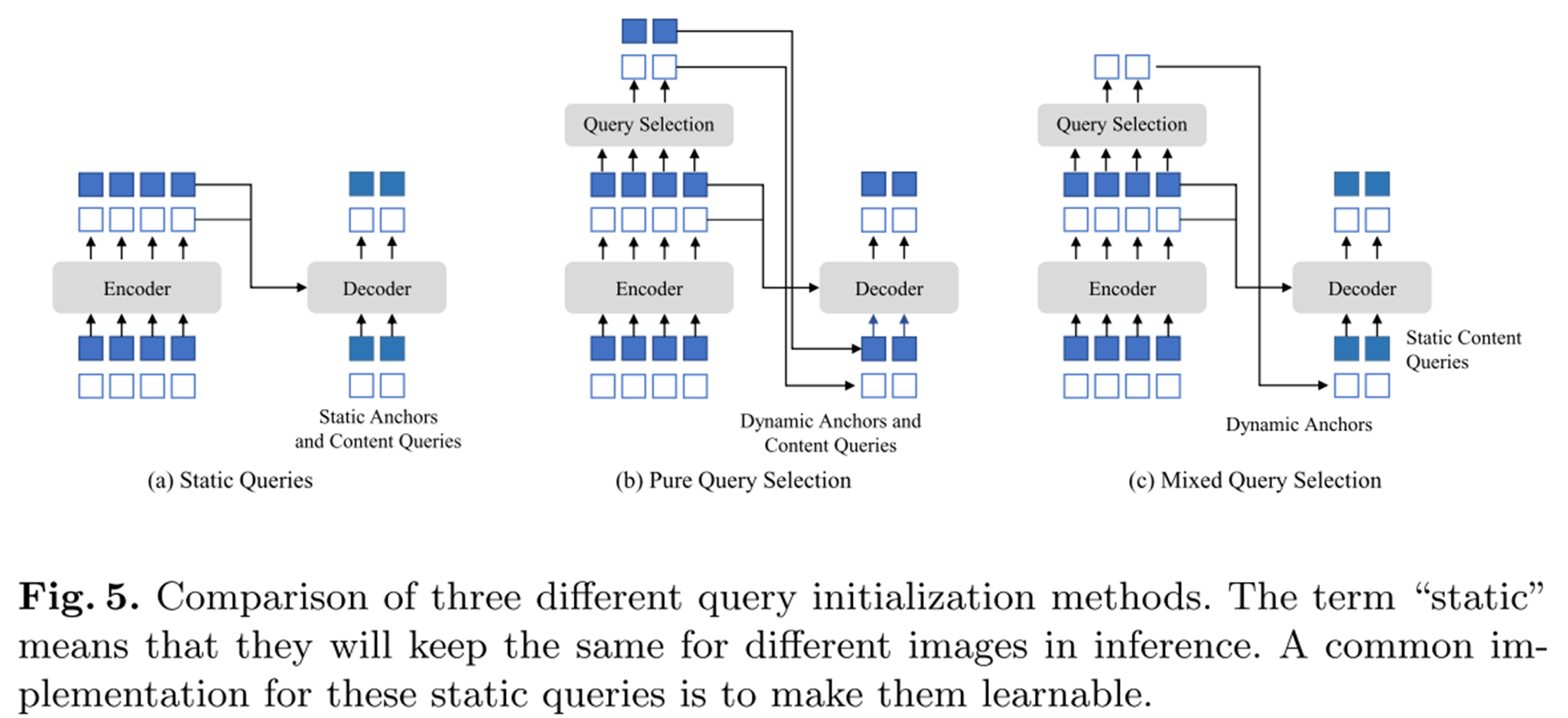
이 부분은 간단하게 그림을 통해 설명드리겠습니다.
아래의 그림에서 보시다시피, (a) (b) (c) 그림을 다음과 같이 구분할 수 있습니다.
(a) 정적 쿼리 - 포지셔널 쿼리를 직접 학습하고 이미지 특성(Contents) 쿼리를 고려하지 않음
(b) 동적 쿼리 - 포지셔널 및 이미지 특성 쿼리 둘 다 학습
(c) 혼합 쿼리 - 이미지 특성 쿼리는 정적으로 두고 포지셔널 쿼리를 동적으로 학습
동적 쿼리에서는 전부 쿼리 선정(Query Selection)이 이루어지기 때문에 이미지 특성 정보가 소실될 수 있습니다.
이에 DINO에서는 혼합 쿼리 선정 기법을 통해 이 문제를 개선했습니다.
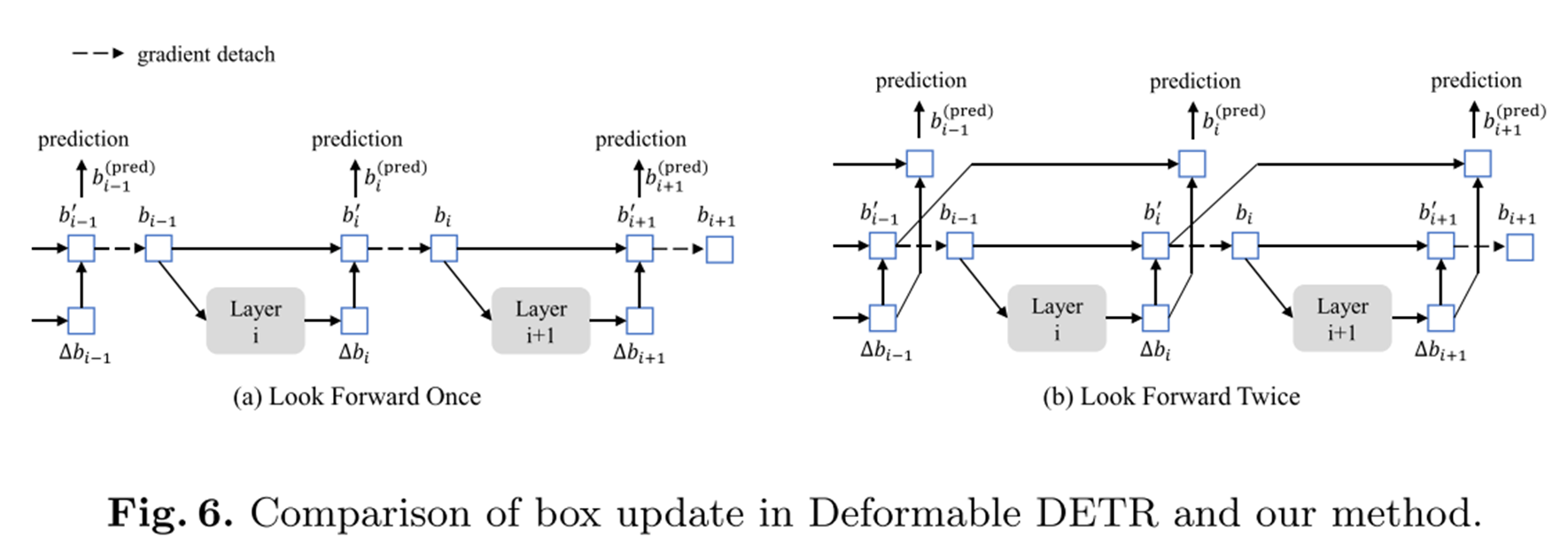
Look forward Twice
Look forward Twice 기법 또한 그림 위주로 설명드리겠습니다.
(a)의 경우 기존의 Look forward Once 기법으로 안정적인 학습을 위해서 레이어간 그래디언트 전파를 차단합니다.
(b)는 Look forward Twice로 해당 레이어의 Loss가 다음 레이어까지 전달됩니다.
DINO는 Look forward Twice 기법을 통해서 학습 수렴 속도를 가속화했으며, 그 결과 또한 개선할 수 있었다고 합니다.
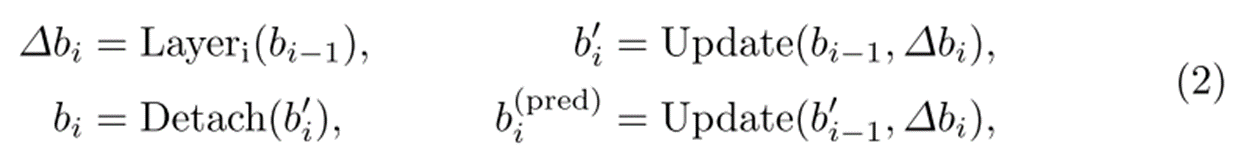
Model Architecture
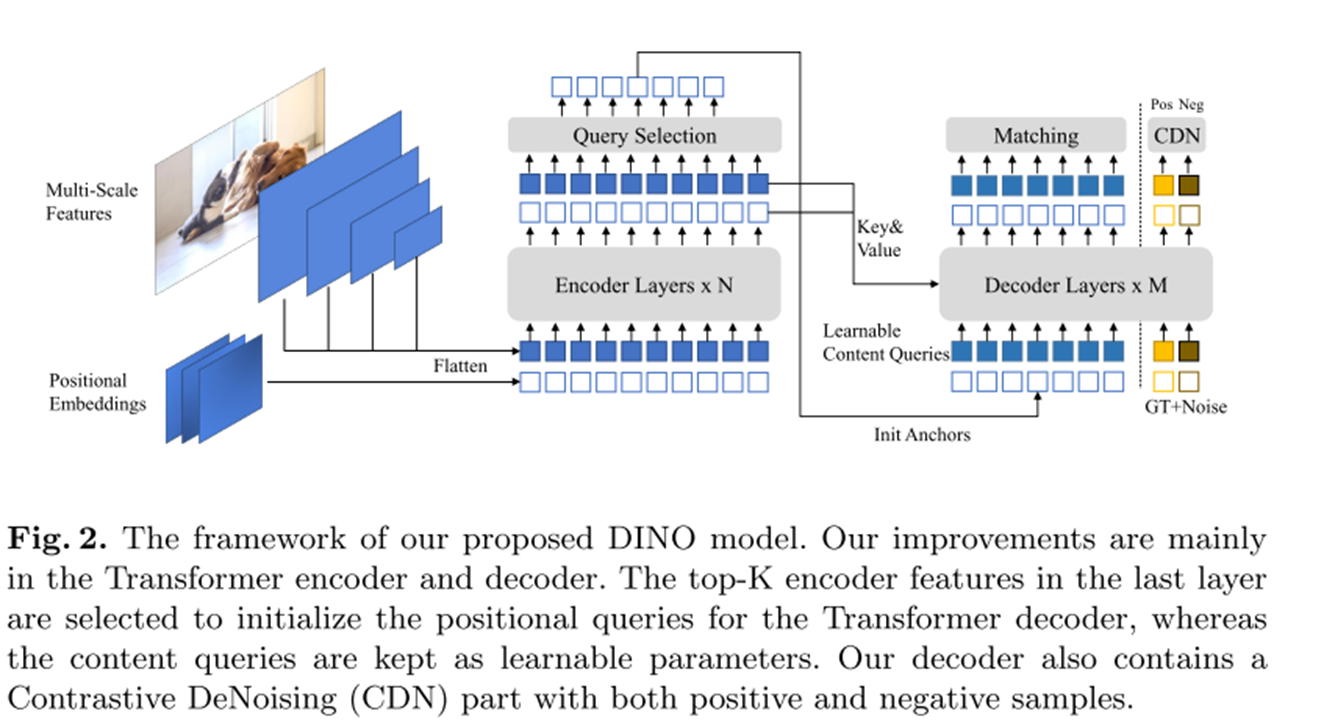
위 3개의 Key Idea를 가지고 모델 학습 파이프라인을 정리해보겠습니다.
1. ResNet, Swin 등의 백본 모델에서 다중 스케일 이미지 특성 추출
2. 이미지 특성에 대한 Positional Embedding으로 인코더에 입력
3. 디코더에서 Positional Query를 활용하여 앵커 박스 초기화(Mixed Query Selection)
4. Deformable Attention 연산(Look forward Twice)
5. 최종 출력값은 예측된 앵커 박스 및 분류 결과
6. Constrative Denoising을 통한 앵커 박스 및 분류 결과 개선
Experiment
실험에서는 COCO 2017 object detection dataset을 Fine-Tuning 했으며, 백본 모델은 ImageNet-22k SwinL 가중치를 활용했다고 합니다.
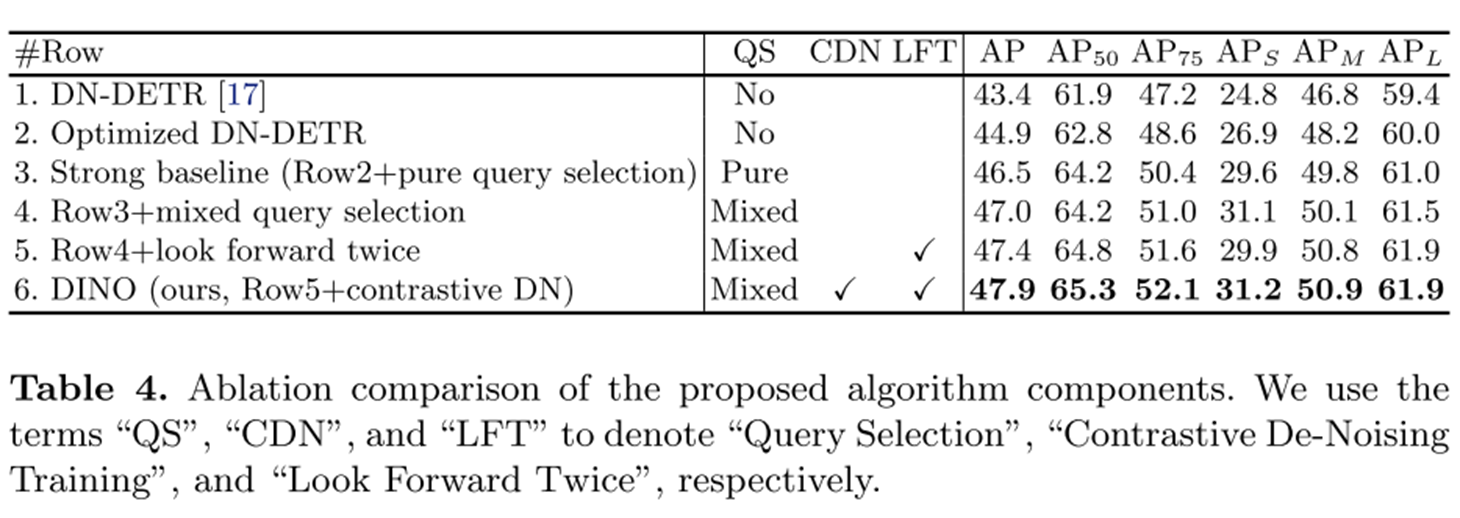
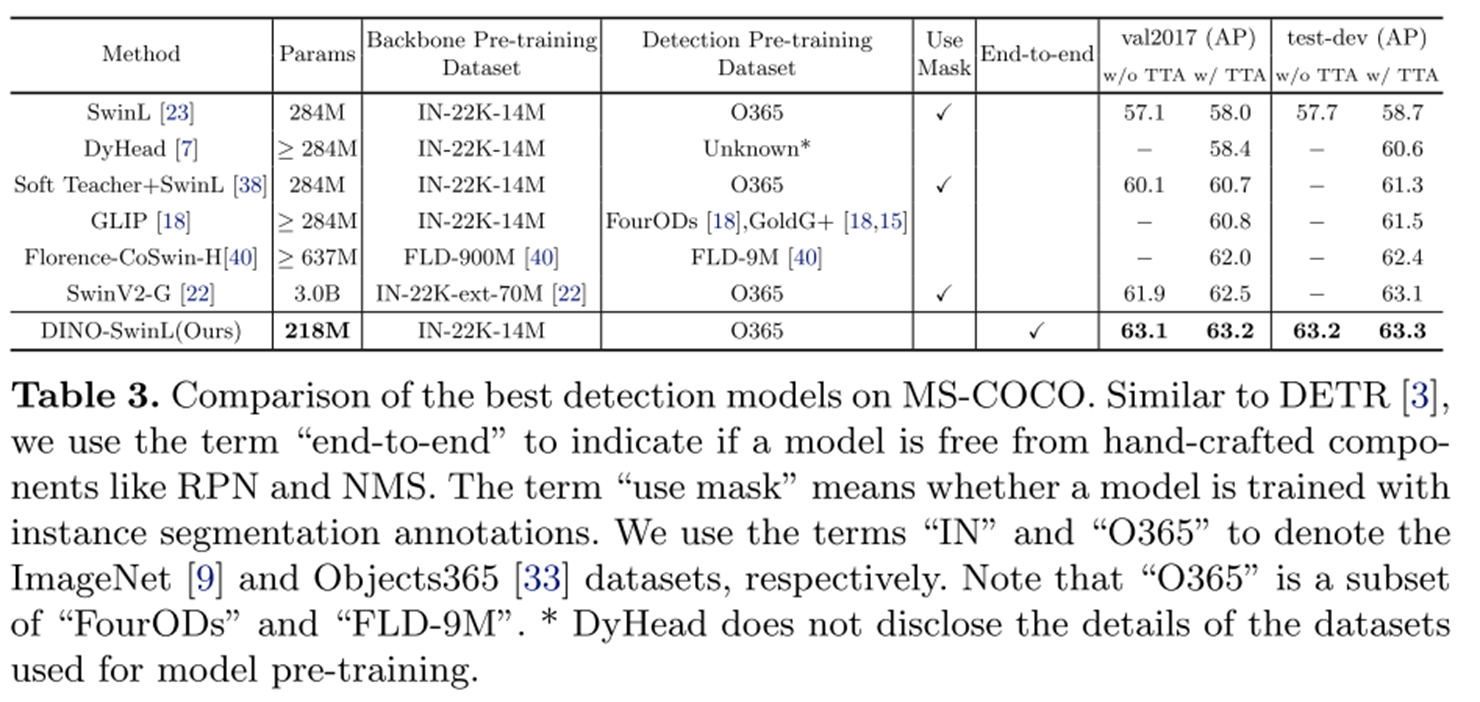
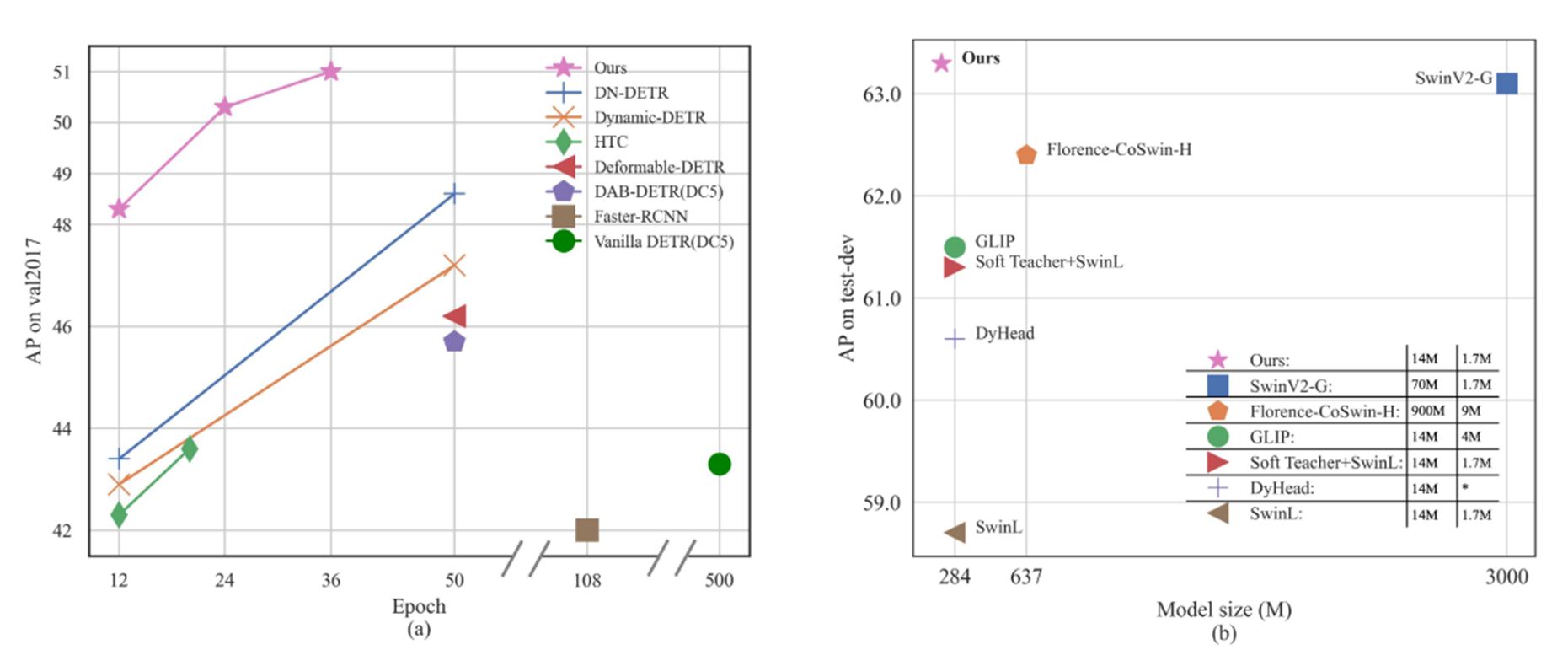
Key Idea 기법들을 적용한 결과 모델 성능이 개선되는 수치가 나타납니다.
특히 다른 SOTA와의 비교에서 파라미터 수, 성능에서 압도적인 성과를 달성했습니다!
마무리
DINO는 기존 Dyhead, SwinV2 등의 알고리즘과 다르게 DETR 기법에서 확장된 버전으로 현재 Object Detection on COCO test-dev에서 1위 자리를 차지하고 있습니다.
특히 주목할만한 점은 빠른 학습 수렴 속도와 적은 수의 가중치로 다른 객체 탐지 분야 SOTA와 비교했을 때 매우 효율적인 결과로 판단됩니다.
앞으로 객체 탐지 분야에서 DETR 기반의 확장 버전이 더 등장할수도 있을 것 같다는 기대감이 듭니다.
논문 원문을 직접 읽고 리뷰하면서 잘못된 부분이 있을 수 있습니다.
논의 및 지적 사항에 대해서는 댓글 남겨주세요.
읽어주셔서 감사합니다!
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L. M., & Shum, H.-Y. (2022). Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605.
'기술 블로그' 카테고리의 다른 글
| AI가 블로그를 대신 써준다고? 텍스트 생성 AI로 기술 블로그 써보기 (0) | 2023.02.02 |
|---|---|
| SAINT, 정형데이터 분석을 위한 최첨단 딥러닝! (0) | 2022.08.04 |
| SOTA 알고리즘 리뷰 6 - SciNet (0) | 2022.03.29 |
| Neural Prophet, 간단한 트렌드 예측과 다양한 해석 (4) | 2022.02.28 |
| AI 윤석열과 이재명 챗봇, 대선 속의 AI (0) | 2022.02.07 |



