
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 악성댓글
- 거대언어모델
- 프롬프트
- GPT
- 머신러닝
- 프롬프트 엔지니어링
- IT
- AI
- 빅데이터
- 모델링
- TabNet
- LLM
- 딥러닝
- LLM 성능 개선
- mergekit
- GPT3
- ChatGPT
- 프롬프트 페르소나
- 프롬프트 잘 쓰는법
- 컴퓨터 비전
- ChatGPT 잘 쓰는 법
- 강화학습
- 프롬프트 잘 쓰는 법
- 경진대회
- chatgpt 꿀팁
- Transformer
- 비전러닝
- GaN
- 인공지능
- SOTA
- Today
- Total
빅웨이브에이아이 기술블로그
Neural Prophet, 간단한 트렌드 예측과 다양한 해석 본문
시작
안녕하세요 ! 빅웨이브에이아이 이병우입니다.
오늘 여러분들께 소개드릴 내용은 바로 페이스북(현 메타)에서 개발한 시계열 예측 패키지인 Neural Prophet 입니다.
데이터 분석에서 빠질 수 없는 것 중 하나가 바로 시계열 분석이죠!
시계열 분석이란 주가, 에너지 사용량 등 시간적인 속성을 가지고 있는 데이터를 분석(예측)하는 것을 의미합니다.
하지만 시계열 분석은 아주 까다로운 분석입니다.
장기적인 관점에서 예측 시 활용할 수 있는 데이터에 한계점이 있기 때문입니다.
이런 까다로운 시계열 분석을 쉽게 할 수 있는 패키지로 Prophet이라는 것이 있었습니다.
하지만 데이터의 비선형적인 요소 및 연속함수의 특징들을 반영하거나 시계열 데이터의 패턴 변동성이 큰 부분들을 반영하기에는 부족한 패키지였죠.
페이스북(현 메타)은 이를 해결하기 위해 기존 Prophet 모델에 신경망(Neural Network)을 추가하여 시계열 분석을 할 수 있도록 Neural Prophet을 개발했습니다!
기존의 Prophet의 우수한 성능과 해석 가능성, 설정 및 사용 용이성의 장점을 유지하며 성능을 높이게 되었습니다.
이제 우리는 시계열 분석 모델에 신경망이 포함된 Neural Prophet 패키지를 통해 쉽고 간단하게 시계열 분석을 구현할 수 있게 된 것이죠!

이제는 Neural Prophet이 어떤 원리로 예측을 수행하는지에 대해서 알아보도록 하겠습니다.
Neural Prophet
Prophet은 시계열 예측 성능보다는 손쉬운 사용, 예측 결과에 해석에 초점을 맞춘 알고리즘입니다.
딥러닝 기술을 기반으로 개발된 우수한 기법(예: TFT)들이 존재하지만, 수요 예측과 같은 비즈니스적인 시사점이 필요할 때 Prophet은 아주 유용하게 활용될 수 있습니다.
하지만 기존의 Prophet 모형은 단기 시점 예측을 위한 로컬 컨텍스트(local context)를 활용하지 못하고, Stan이라는 프로그래밍 언어로 개발되어 확장성의 부분에서 문제점이 있습니다.
Neural Prophet은 자기 회귀 및 공변량 모듈로 로컬 컨텍스트 문제를 해결하고, Pytorch를 기반으로 개발되어 개발자들이 쉽게 소스코드에 접근할 수 있습니다.
Prophet의 우수한 해석력을 유지하면서 예측 성능을 개선(55~92%)했다는 점에서 공헌점이 있다고 볼 수 있습니다.

Neural Prophet의 핵심적인 개념은 바로 모듈식 구성이 가능하다는 점입니다.
위의 그림처럼 Neural Prophet은 각 변수가 예측 결과에 영향을 미치는 구조입니다.
위의 구성 요소를 간단하게 살펴보면,
Trend(T): piece-wise 선형 함수를 활용하여 비선형 트렌드를 예측
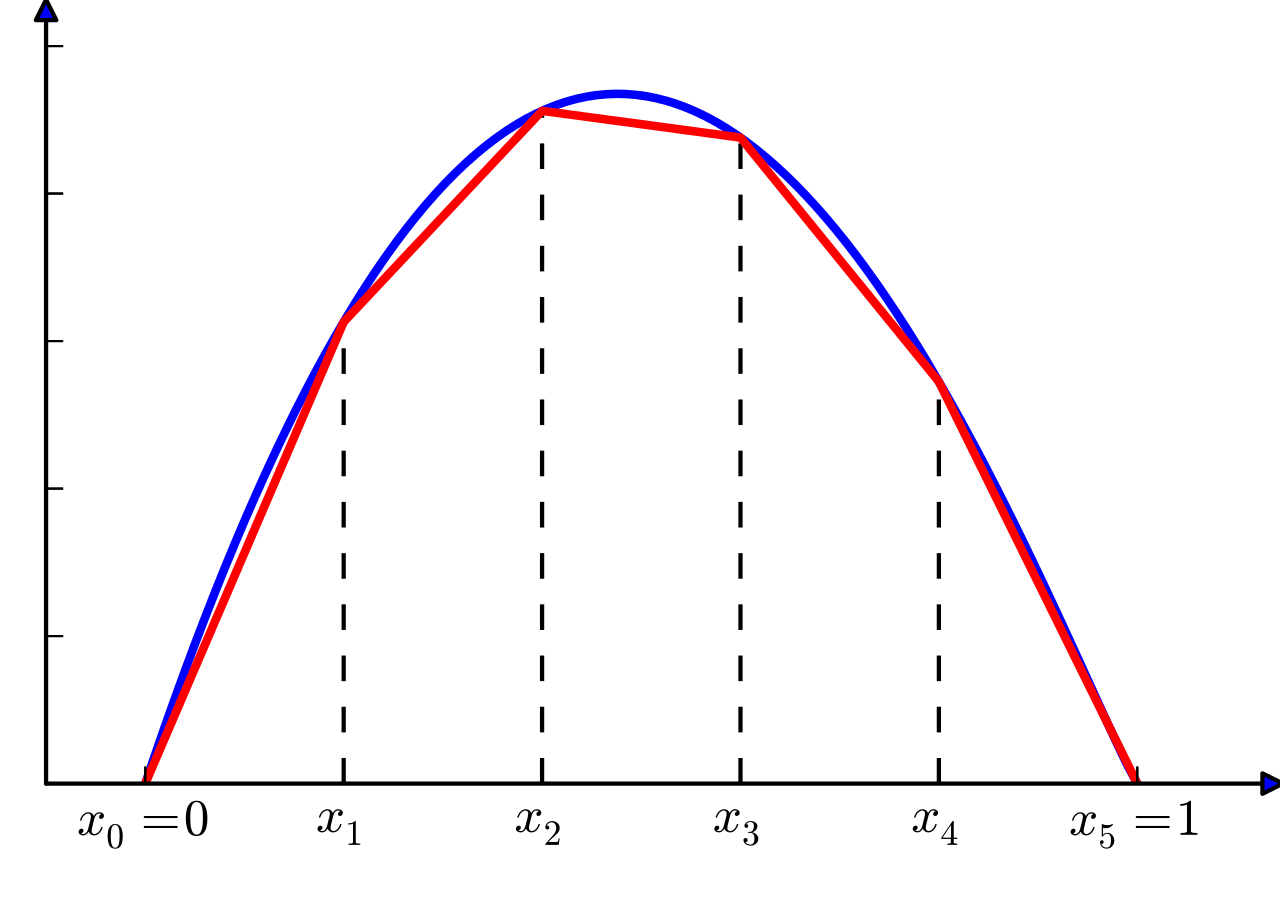
Seasonality(S): 여러 개의 Fourier terms를 활용, 한 가지 패턴만을 분석하는 것이 아니라 다중 계절성을 포착Auto-Regression(A): 기존 클래식 AR에서 전방향 신경망 네트워크를 적용한 AR-Net 활용
Lagged Regressors(L): 모델 해석에 적용되는 변수들(공변량)
Future Regressor(F): 미래에 이미 알 수 있는 변수들을 회귀 예측에 활용
Event & Holidays(E): 사용자 정의 이벤트(할인 행사, 특가 등), 공휴일 등을 모델링에 반영
Neural Prophet Baseline
간단한 예제를 통해서 코드를 실행해보겠습니다.
아래의 링크로 들어가시면 소스 코드를 확인하실 수 있습니다.
https://colab.research.google.com/drive/1KeSiaZvCEJzB35f6WPYl3TyDjaSlDWwK
모든 코드 프로세스는 처음부터 끝까지 실행만 하면 돌아가도록 설계되었습니다.
패키지 및 데이터 임포트
<패키지 다운로드>
if 'google.colab' in str(get_ipython()):
! pip install git+https://github.com/ourownstory/neural_prophet.git # 코랩 구동 시 패키지 설치
# pip install neuralprophet
# 간단하고 빠르게 설치할 수 있지만, 최신 버전에서의 버그가 발생할 수 있음코랩에서 git URL을 통해 neuralpropeht 패키지를 설치합니다.
<패키지 임포트 및 데이터 다운로드>
#패키지 임포트
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
set_log_level("ERROR")
#구글 드라이브 다운로드 패키지
from google_drive_downloader import GoogleDriveDownloader as gdd
#데이터 다운로드
gdd.download_file_from_google_drive(file_id='1JRslcolP0XJDQKfXrYl82eyDTCETuzjl',
dest_path='data/energy.zip',
unzip=True)패키지를 임포트 후 데이터를 google_drive_downloader로 다운로드 합니다.
google_drive_downloader를 활용하면 코랩 환경에서 구글 드라이브 마운트 없이 쉽게 데이터를 임포트할 수 있습니다.
다른 데이터로 직접 해보실 분들은 구글 드라이브 공유 URL에서 ID만 따로 file_id 변수에 지정하면 됩니다.
예) 구글 드라이브 링크: https://drive.google.com/file/d/1JRslcolP0XJDQKfXrYl82eyDTCETuzjl/view?usp=sharing
file_id = '1JRslcolP0XJDQKfXrYl82eyDTCETuzjl'
<데이터 임포트>
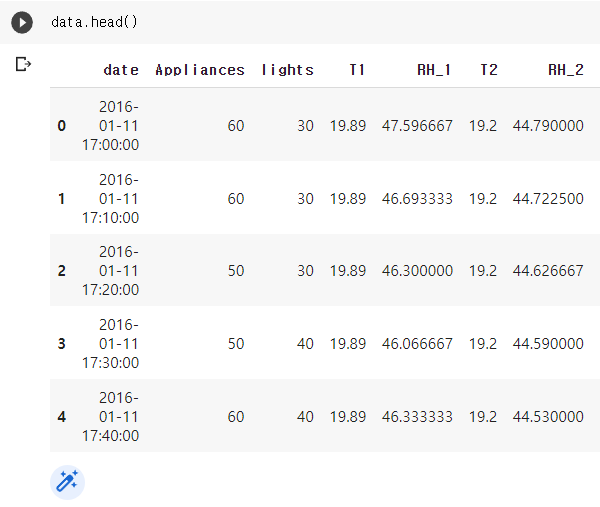
data = pd.read_csv('data/KAG_energydata_complete.csv')
data.head()데이터를 임포트하고 확인합니다.
예제의 데이터는 시계열적으로 구성된 Kaggle의 에너지 사용량 예측 관련 데이터셋입니다.
아래의 이미지에서 우리는 'Appliances'를 예측해야 합니다.
데이터 전처리 및 모델 학습
<학습, 테스트 데이터 분할>
#train test split
cutoff = "2016-05-01"
train_df = data[data['date']<cutoff]
test_df = data[data['date']>=cutoff]학습과 검증을 위해서 2016년 5월 1일 이후를 테스트 데이터셋으로 분할합니다.
5월 이전의 데이터로 Neural Prophet이 패턴을 학습하여 이후의 데이터로 모델 성능을 평가합니다.
<학습용 데이터셋, 모델 생성 및 학습>
#전용 train, test 데이터 생성
train = pd.DataFrame({"ds": train_df["date"], "y": train_df["Appliances"]})
test = pd.DataFrame({"ds": test_df["date"], "y": test_df["Appliances"]})
#모델 설정
m = NeuralProphet(
learning_rate=0.1,
)
#모델 학습
metrics = m.fit(train, freq="H")학습용 데이터셋을 따로 생성(train, test 변수)합니다.
모델 학습을 위해서 dict 형태로 key 값(ds, y)을 맞춰줍니다.
Neural Prophet의 파라미터는 기본 설정만 맞추고 freq(예측 시점)을 H로 설정합니다.
freq를 H로 설정하면 1시간 단위씩 모델이 예측하는 방식으로 학습됩니다.
시각화 검증
<모델 예측 시각화(학습 데이터)>
#학습 데이터셋 예측 결과 시각화
train_pred = m.predict(train)
#fig = m.plot(train_pred)
fig1 = m.plot(train_pred[-30*24*6:])
fig2 = m.plot(train_pred[-7*24*6:])
#comp = m.plot_components(train_pred)
param = m.plot_parameters()m.predict와 같은 간단한 코드를 통해서 모델의 예측값을 생성할 수 있습니다.
학습 데이터의 예측 결과를 실험했을 때, 어느 정도의 패턴을 학습한 모습입니다.
위의 코드가 6개의 그래프를 생성하기 때문에 아래의 코드 결과에서 모델 예측 결과를 해석해보겠습니다.
<모델 예측 시각화(테스트 데이터)>
#테스트 데이터셋 예측 결과 시각화
test_pred = m.predict(test)
#fig = m.plot(test_pred)
fig1 = m.plot(test_pred[-14*24*6:])
fig2 = m.plot(test_pred[-7*24*6:])
#comp = m.plot_components(test_pred)
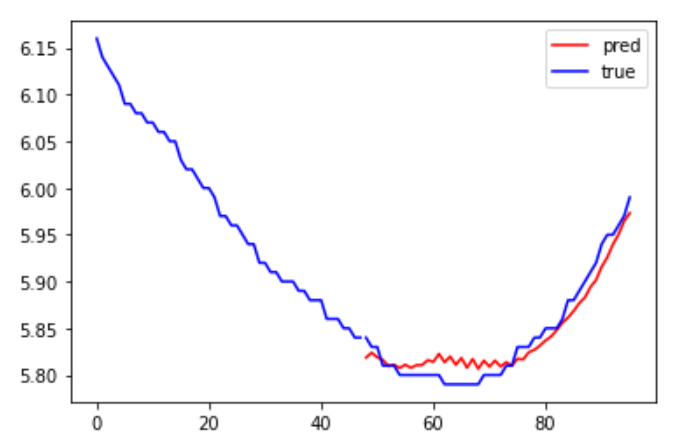
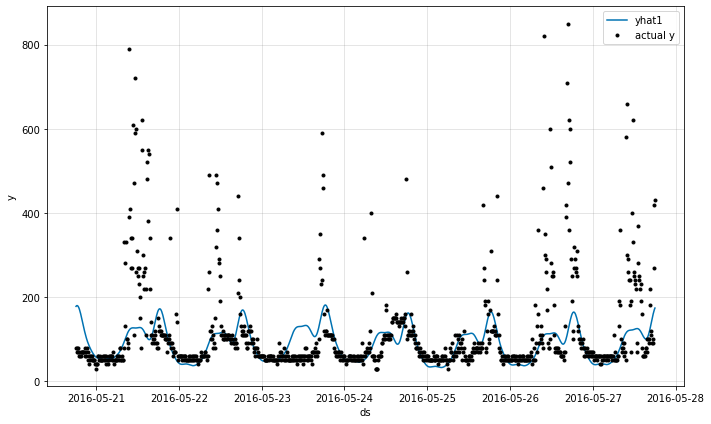
param = m.plot_parameters()테스트 데이터셋에서 모델을 검증했을 때, 전반적인 패턴은 분석할 수 있지만 극단적인 수치에서는 예측이 제대로 수행되지 않았습니다.
단변량 베이스라인 모델을 활용했기 때문에 단순한 패턴으로만 예측하는 형태가 나타납니다.
m.plot에서 test_pred의 -14*24*6 기간을 설정했는데, 이는 데이터가 10분 단위 데이터라서 2주간의 예측 결과를 시각화한 것입니다.
데이터에 맞게 예측 기간을 맞춰서 시각화를 할 수 있습니다.
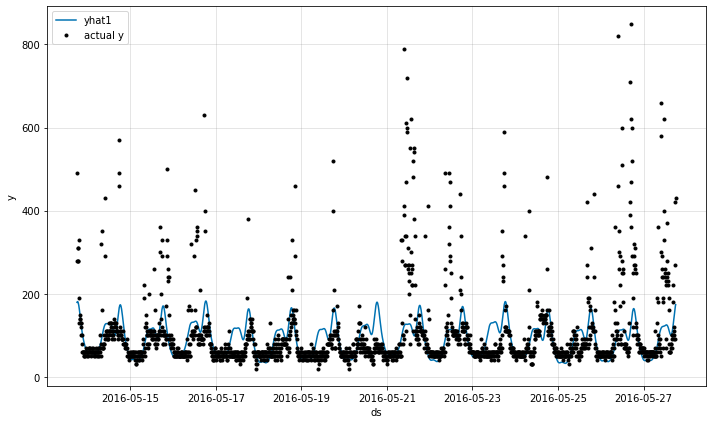
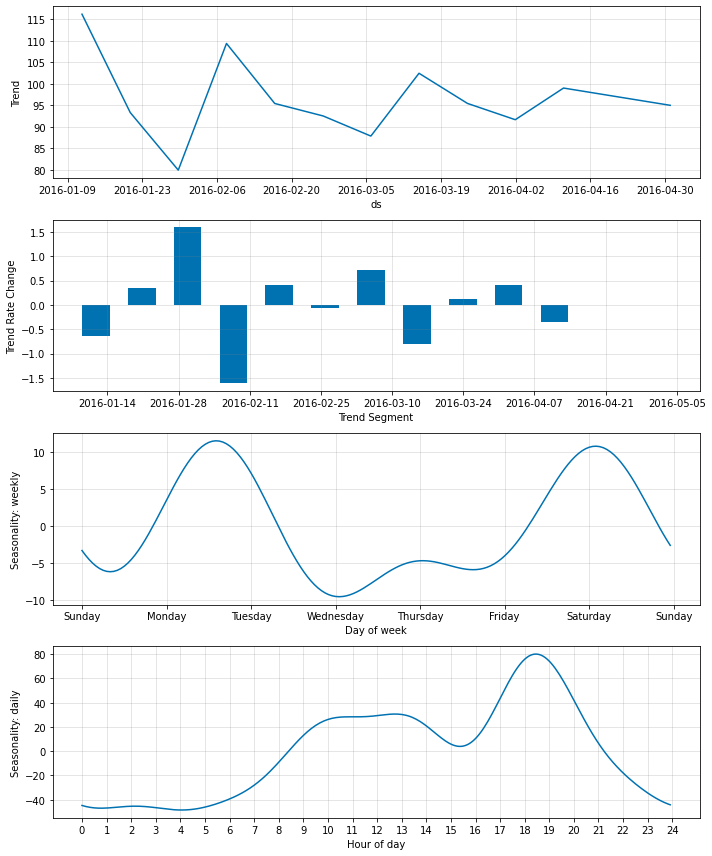
m.plot_parameters() 기능은 Neural Prophet의 회귀 변수에 대한 분석 결과를 시각화합니다.
단순하게 특성의 중요도를 산출할 수 있는 수준에서 확실히 여러가지 모델 예측 결과에 대한 해석을 제공하는 모습입니다.
<모델 성능 평가(학습 데이터)>
from sklearn.metrics import mean_absolute_error, mean_squared_error, mean_absolute_percentage_error
col = "Appliances"
#학습 데이터셋 검증
pred2 = train_pred["y"]
test2 = train_pred['yhat1']
print("============== {} Evaluate Result============".format(col))
print("MAE :", mean_absolute_error(test2, pred2))
print("MSE :", mean_squared_error(test2, pred2))
print("RMSE :", (mean_squared_error(test2, pred2))**2)
print("MAPE :", mean_absolute_percentage_error(test2, pred2))============== Appliances Evaluate Result============
MAE : 53.529329394921895
MSE : 9436.841060817815
RMSE : 97.14340461821284
MAPE : 0.49206725963046455
학습 데이터셋에서는 위와 같은 결과가 나타납니다.
시계열 예측에서는 보통 회귀분석(수치 예측)을 수행하는데, 가장 일반적으로 활용하는 지표는 MAE(Mean Average Error)입니다.
MAE는 하나의 예측 결과에 대한 평균적인 오차로, 하나의 전기 사용량을 예측할 때마다 53.53 정도의 오차가 발생한다고 보시면 됩니다.
전기 사용량의 수치가 평균 94, 중위값이 60으로 나타나는 것을 고려하면, 다소 아쉬운 결과로 해석됩니다.
<모델 성능 평가(테스트 데이터)>
#테스트 데이터셋 검증
pred2 = test_pred["y"]
test2 = test_pred['yhat1']
print("============== {} Evaluate Result============".format(col))
print("MAE :", mean_absolute_error(test2, pred2))
print("MSE :", mean_squared_error(test2, pred2))
print("RMSE :", (mean_squared_error(test2, pred2))**2)
print("MAPE :", mean_absolute_percentage_error(test2, pred2))============== Appliances Evaluate Result============
MAE : 42.99558557054454
MSE : 6437.301358113935
RMSE : 80.23279477940386
MAPE : 0.4250625800055133
최종적으로 테스트 데이터에 대해 모델 예측을 수행했을 때, MAE 42 정도가 측정됩니다.
위의 예측 결과 시각화 자료에서 확인되는 것과 같이 이상치가 많고 수치가 높기 때문에 MSE가 매우 높은 수준으로 확인됩니다.
마무리
이번 포스트에서는 Neural Prophet의 이론과 베이스라인 코드 구현에 대해서 소개드렸습니다.
베이스라인을 보시면 아시겠지만 정말 간단한 코드로 다양한 결과를 나타낼 수 있습니다.
하지만 빅웨이브에서 따로 Neural Prophet 코드를 고도화하여 실험을 진행했는데, 모델 성능적인 측면에서는 다소 아쉬운 부분이 있었습니다.
그렇지만 예측 결과에 대한 해석적인 측면에서는 어떠한 시계열 예측 기법보다도 우수하며 코드를 간단하게 구현할 수 있다는 것이 큰 장점으로 판단됩니다.
실제로 Prophet이 2018년에 소개된 이후로 유용하게 활용되었던 이유가 여기에 있습니다.
Prophet을 개선한 Neural Prophet은 앞으로도 트렌드 예측의 비즈니스적 활용에서 큰 주목을 받을 것으로 예상됩니다.
Neural Prophet 예제에 관련된 다양한 포스트는 지속적으로 빅웨이브에서 소개할 예정입니다.
읽어주셔서 감사합니다!
Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72 (1), 37-45.
Triebe, O., Hewamalage, H., Pilyugina, P., Laptev, N., Bergmeir, C., & Rajagopal, R. (2021). NeuralProphet: Explainable Forecasting at Scale. arXiv preprint arXiv:2111.15397.
'기술 블로그' 카테고리의 다른 글
| SOTA 알고리즘 리뷰 7 - DINO (3) | 2022.05.31 |
|---|---|
| SOTA 알고리즘 리뷰 6 - SciNet (0) | 2022.03.29 |
| AI 윤석열과 이재명 챗봇, 대선 속의 AI (0) | 2022.02.07 |
| SOTA 알고리즘 리뷰 5 - MobileViT (4) | 2022.01.10 |
| 오징어 게임에도 인공지능이? - 비디오 인스턴스 세그멘테이션(Video Instance Segmentation) (0) | 2021.10.19 |



