
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- LLM
- 거대언어모델
- 딥러닝
- 프롬프트
- 모델링
- LLM 성능 개선
- 머신러닝
- AI
- 비전러닝
- 컴퓨터 비전
- 프롬프트 잘 쓰는 법
- GaN
- chatgpt 꿀팁
- 빅데이터
- 강화학습
- GPT
- GPT3
- Transformer
- TabNet
- ChatGPT 잘 쓰는 법
- 프롬프트 페르소나
- 경진대회
- ChatGPT
- 인공지능
- IT
- 프롬프트 잘 쓰는법
- mergekit
- 프롬프트 엔지니어링
- 악성댓글
- SOTA
- Today
- Total
빅웨이브에이아이 기술블로그
SOTA 알고리즘 리뷰 5 - MobileViT 본문
시작
안녕하세요! 빅웨이브에이아이 이현상입니다.
지난 포스트에서 ViT-G/14에 대해서 소개드렸죠?
구글에서는 최근 TFT, TabNet, ViT 등 다양한 분야에서 트랜스포머 기법을 응용하여 우수한 성능을 달성하고 있습니다.
그런데 대표적인 SOTA 알고리즘 소개 사이트인 'paperwithcode'의 이미지 분류 분야를 보면 파라미터 수가 참 어마어마하죠?
ImageNet 벤치마크 상위 4개 알고리즘은 모두 파라미터 개수가 1,000M(10억개)이 넘습니다!

파라미터 수가 10억개를 넘는 모델을 개인이 활용하거나 모바일 기기에 탑재하기에는 어려움이 있습니다.
그래서 딥러닝 모델을 실용적으로 활용하기 위한 효율적인 경량화도 딥러닝 분야에서 굉장히 중요한 요소 중 하나입니다.
Andrew Howard, Mark Sandler는 2017년부터 딥러닝 이미지 분류 모델의 경량화 버전인 MobileNet을 연구하고 있고 2019년 MobileNet v3까지 연구를 발표한 상황입니다.
트랜스포머 기반 비전 모델은 이러한 점에서 CNN 기반 모델보다 실용적이지 못하다는 한계점을 지적받았습니다.
그런데 2021년 10월 5일, Sachin Mehta, Mohammad Rastegari가 MobileViT를 발표했습니다.
트랜스포머 기반 비전 모델에서도 경량화 버전이 드디어 나온 것입니다!
오늘은 Sachin Mehta, Mohammad Rastegari의 MobileViT 논문을 소개드리겠습니다.
Key Idea
CNN 모델은 컨볼루션 레이어를 통해서 이미지의 로컬 영역을 분할하여 효율적으로 학습하는 방식입니다.
CNN은 확실히 이미지 분류 문제에서 효율적이지만 로컬 영역을 분할하고 차원을 축소하는 과정에서 정보 손실이 발생합니다.
ViT는 전역적 표현(global represenation)을 학습할 수 있지만 CNN에 비교적 너무 무거워서 실제 임베디드 기기에 활용하기 어려울 수 있습니다.
MobileViT는 ViT에 CNN의 장점을 결합하여 이미지의 전역적 표현을 효율적으로 학습할 수 있도록 모델 네트워크를 재구성했습니다.
기존 ViT 모델은 이미지를 겹치지 않는 패치 시퀀스로 분할하여 다중 헤드 셀프 어텐션(multi-headed self-attention) 트랜스포머로 학습하는 방식입니다.
여기서 MobileViT는 3가지 방식에 초점을 두고 ViT 모델을 성공적으로 경량화했습니다.
1. 경량화(light-weight)
2. 범용성(general-purpose)
3. 낮은 지연 시간(low latency)
또한 특히 중점적으로 고려한 부분은 텐서 처리에서 로컬 및 글로벌 정보를 모두 효과적으로 인코딩하는 MobileViT Block를 개발했습니다.
아래의 그림을 보면 ViT의 Transformers as Counvolutions 연산 과정이 MobileViT Block으로 대체됩니다.
MobileViT Block은 CNN의 컨볼루션 연산을 트랜스포머 기반 전역적 처리 방식으로 처리합니다.
MobileViT의 모델 구조를 보면 이미지가 컨볼루션 연산을 통해서 MV2(MobileNet V2) 블록으로 입력됩니다.
MV2 블록에서 아래 화살표 표시는 다운 샘플링(down-sampling)을 수행했다는 것입니다.
MobileViT block에서 L은 트랜스포머 블록 수, C,H,W는 각각 텐서의 채널, 높이, 너비를 나타냅니다.
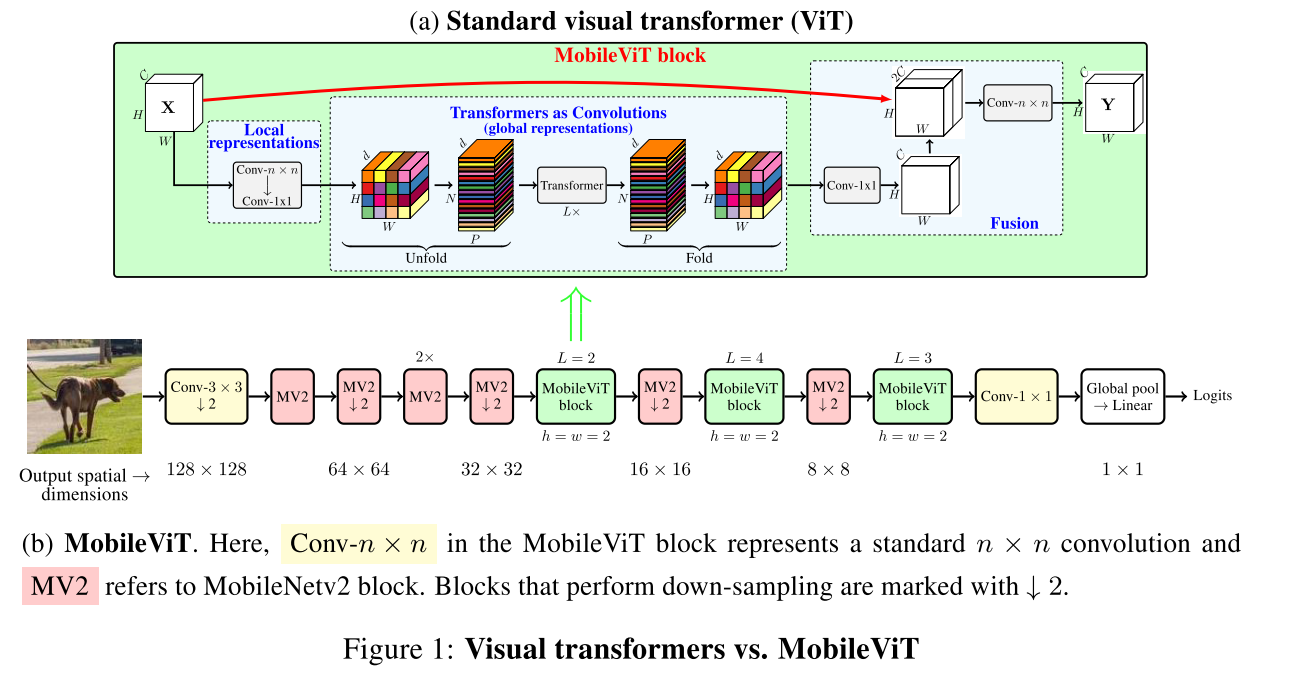
MobileViT 모델 아키텍처
MobileViT Block은 아래의 그림과 같이 빨간색 픽셀의 정보가 트랜스포머를 통해서 파란색 픽셀로 전달됩니다.
파란색 픽셀은 이미 컨볼루션 연산으로 인접 픽셀에 대한 정보가 인코딩되었기 때문에 빨간색 픽셀은 이미지의 모든 픽셀을 대상으로 정보를 인코딩할 수 있습니다.
즉, 같은 위치의 픽셀 정보가 트랜스포머에 의해서 연결되어 글로벌 정보가 모든 픽셀에서 고려될 수 있습니다.
그림의 검은색 격자는 이미지의 패치, 회색 격자는 픽셀을 의미합니다.

ViT에서는 픽셀의 공간 정보를 버리는 반면에 MobileViT는 패치 시퀀스 및 각 패치 내의 공간 시퀀스 정보를 유지합니다.
MobileViT Block의 연산 과정을 정리해보겠습니다.
1. 입력 텐서에 대해서 n x n 컨볼루션 레이어를 적용하여 로컬 공간 정보 인코딩
2. point-wise 컨볼루션 레이어 적용하여 텐서를 고차원 공간으로 투영
3. 공간 유도 바이어스(spatial inductive bias) 트랜스포머 연산을 통해서 이미지의 글로벌 표현 학습
4. 다시 point-wise convolution을 통해서 저차원 공간으로 투영
5. n x n 컨볼루션 레이어를 활용하여 텐서의 로컬 및 글로벌 정보를 융합
여기서 point-wise convolution이란 1 x 1 커널을 가지는 컨볼루션 레이어를 의미합니다.
위의 절차를 통해서 MobileViT 모델은 이미지의 모든 픽셀을 수용 영역(receptive field)로 확장할 수 있습니다.
효율적인 학습을 위한 다중 스케일 샘플러
MobileViT 모델은 효율적인 학습을 위해서 다중 스케일 샘플러를 활용합니다.
현실 세계의 이미지는 다양한 해상도를 가지고 있기 때문에 테스트 환경에서 다중 스케일링 학습이 필요합니다.
MobileViT는 위치 임베딩(positional embedding)이 필요하지 않기 때문에 다중 스케일 학습 방식이 효율적입니다.
기존 연구에서의 이미지 학습 방식은 최대 공간 해상도를 기준으로 배치 사이즈를 설정합니다.
MobileViT 모델에서는 저해상도 구간에서 배치 사이즈를 크게 설정하는 로직이 적용되어 더 빠르고 효율적인 학습이 가능합니다.

실험 결과
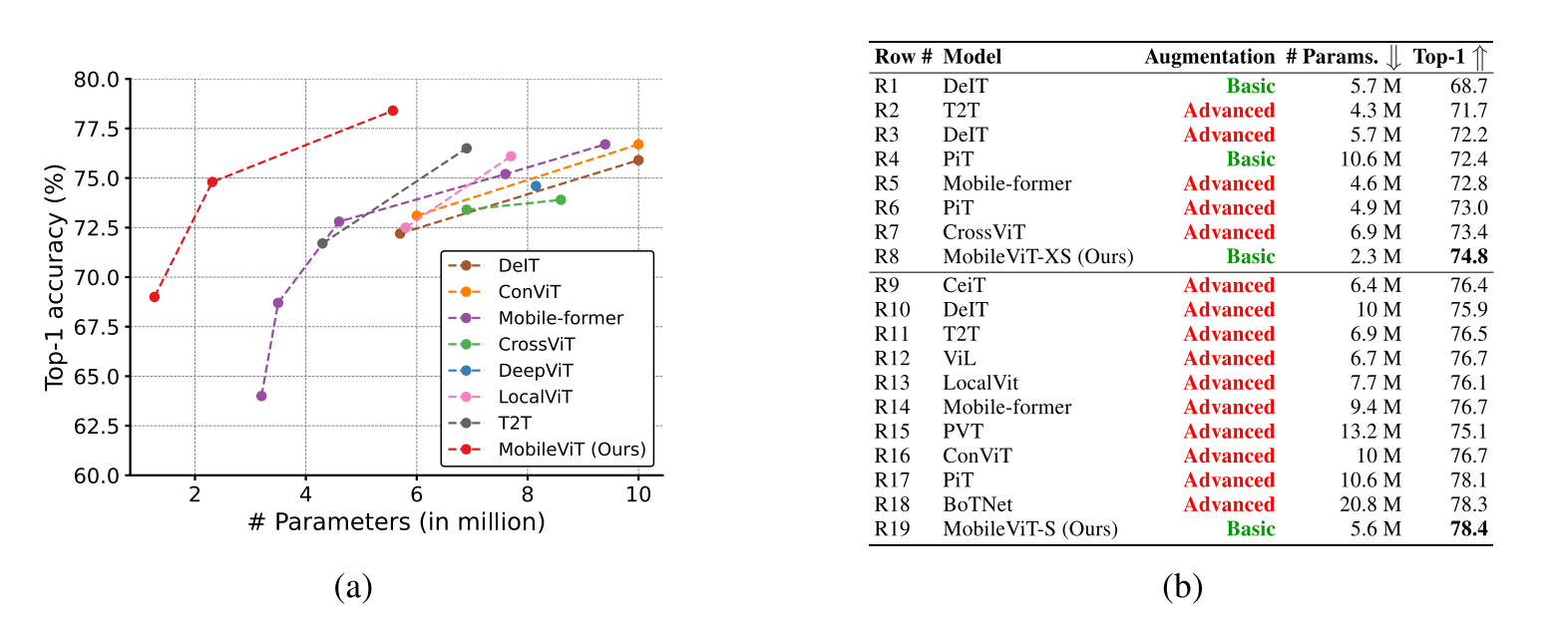


기타 이슈
MobileViT 모델은 모바일 환경에서 실시간 이미지 처리 테스트 시 기존 MobileNetv2에 비교적 상당히 느린 속도가 측정되었습니다.
논문에서 이는 모바일 장치에서의 트랜스포머 모델의 최적화 기능을 활용할 수 없기 때문이라고 합니다.
2021년 10월에 MobileViT 모델이 개발되었기 때문에 모바일 기기에서도 트랜스포머 최적화 기능이 관련 패키지에 업데이트될 수 있기를 기대합니다!

마무리
처음 ViT를 접했을 때 굉장히 신선한 접근이라고 생각은 했지만, 모델이 무겁고 복잡성이 높기 때문에 실무에서는 적용하기 어려운 알고리즘으로 느껴졌습니다.
하지만 MobileViT 연구는 현실 세계에서 트랜스포머 기반 알고리즘을 구현하고자 하는 시도입니다.
아직 추가적인 연구가 필요한 부분이지만 현재 SOTA 알고리즘 중 트랜스포머 기반 모델들이 성능적으로 기존 딥러닝의 한계점을 극복하고 있는 상황에서 아주 중요한 공헌점을 남겼다고 볼 수 있겠습니다.
트랜스포머와 함께 이제는 기존 CNN, LSTM의 한계를 뛰어넘는 새로운 세대로 딥러닝 분야가 발전하고 있습니다.
논문 원문을 번역하고 정리한 것이다보니 틀린 부분이나 어색한 부분이 있을지도 모르겠습니다.
의견이나 지적, 질문 등은 언제나 환영이니 댓글로 달아주시면 감사하겠습니다.
읽어주셔서 감사합니다!
'기술 블로그' 카테고리의 다른 글
| Neural Prophet, 간단한 트렌드 예측과 다양한 해석 (4) | 2022.02.28 |
|---|---|
| AI 윤석열과 이재명 챗봇, 대선 속의 AI (0) | 2022.02.07 |
| 오징어 게임에도 인공지능이? - 비디오 인스턴스 세그멘테이션(Video Instance Segmentation) (0) | 2021.10.19 |
| 메타 러닝(Few Shot Task) - 적은 데이터로도 성능은 강력하게! (0) | 2021.10.06 |
| 딥러닝, 그거 어떻게 하는 건데? (0) | 2021.09.23 |



