
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 프롬프트
- mergekit
- TabNet
- LLM
- 경진대회
- IT
- 프롬프트 잘 쓰는법
- GaN
- Transformer
- ChatGPT 잘 쓰는 법
- 강화학습
- 머신러닝
- 프롬프트 페르소나
- 딥러닝
- GPT3
- LLM 성능 개선
- 인공지능
- 악성댓글
- GPT
- 모델링
- AI
- SOTA
- 프롬프트 잘 쓰는 법
- 프롬프트 엔지니어링
- 거대언어모델
- 빅데이터
- 컴퓨터 비전
- 비전러닝
- chatgpt 꿀팁
- ChatGPT
- Today
- Total
빅웨이브에이아이 기술블로그
Know Comment API - 차별 및 혐오 표현 탐지 솔루션 본문
안녕하세요! 빅웨이브에이아이 선임 연구원 이현상입니다.
지난 포스트에서는 2020 인공지능 온라인 경진대회의 악성 댓글 분류 task에 대해서 다뤘습니다.
이번에는 이 악성 댓글 분류 기술의 범위를 조금 더 확장하여 범용적인 차별 및 혐오 표현 탐지를 위한 시스템을 소개드리겠습니다.
2020 인공지능 온라인 경진대회의 목적은 인공지능 분야에서 기술이 우수한 기업들을 선정하여 인공지능 관련 사업화를 하는 것입니다.
경진대회를 통해 30개의 우수 기업을 선정하여 사업화를 진행하는데 감사하게도 빅웨이브팀이 선정되어 사업화를 하게 되었습니다.
여기서 빅웨이브에이아이 법인이 설립되게 되었습니다.
빅웨이브 팀의 사업화 주제는 "인공지능 기반 차별 및 혐오 탐지 시스템 개발" 입니다.
데이터베이스 구축
인터넷 뉴스 댓글뿐만 아니라 다양한 인터넷 공간에서 차별 및 혐오 표현의 문제가 심각해지고 있습니다.
온라인 동영상 플랫폼, 인터넷 방송, SNS, 심지어 챗봇에 관련해서도 이와 같은 이슈들이 있었죠.
빅웨이브 팀은 최종적으로 범용적인 분야에 적용할 수 있는 차별 및 혐오 표현 탐지 시스템을 개발하는 것을 목표로 두고 있습니다.
이번 사업화 단계에서 인터넷 뉴스 댓글 데이터 약 50만 건 이상 구축을 했으며, 추후 다른 온라인 플랫폼에도 적용할 수 있도록 데이터 셋을 구축할 예정입니다.
데이터의 총 클래스 개수는 10개로 분류되고 각각 욕설 표현, 비난 표현, 인종 차별, 성 차별, 성희롱, 종교 차별, 외모 차별, 연령 차별, 출신 차별, 정치 차별로 구분됩니다.
차별 및 혐오 표현에 해당하는 세부 카테고리를 예측하기 위해서는 각 클래스에 포함되는 데이터의 수를 충분히 확보해야 합니다.
이를 위해 빅웨이브에이아이는 1차적으로 수집한 데이터에서 분류하는 작업을 수행함으로써 클래스 편향 문제를 해결했습니다.
구체적인 데이터베이스 구축 프로세스는 추후 포스트에서 다루겠습니다.
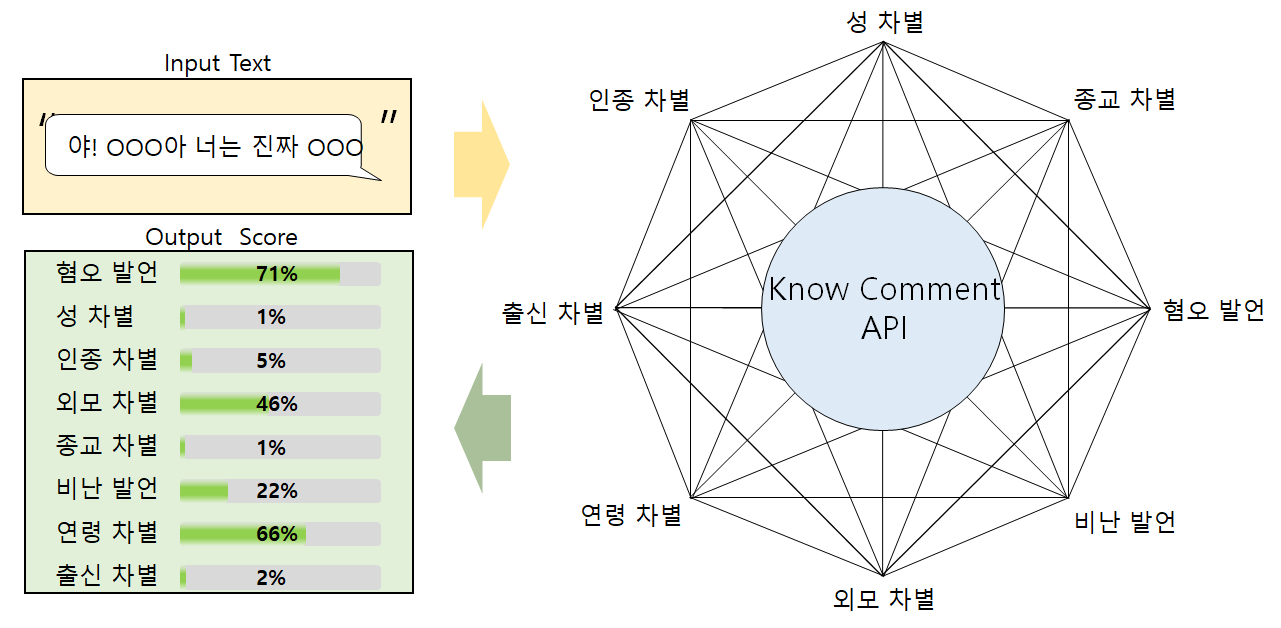
본 데이터 셋은 데이터 전처리 전문인력 5명을 고용하여 이루어졌습니다.
객관성을 확보하기 위해 5명의 레이블링이 일치하는지 크로스 체크를 실시했습니다.
데이터베이스는 AWS dynamo DB에 구축했으며 데이터 파이프라인 및 API 시스템의 자세한 사항은 추후 포스트에서 설명 드리겠습니다.

Know Comment API 시스템 개발

사람들이 말을 할때 인공지능은 이미 그 말이 어떤 의미인지 알고있다!
Know Comment API는 딥러닝 기술을 기반으로 차별 및 혐오 표현 탐지가 가능한 시스템입니다.
레이블링 작업 도중 성희롱, 정치성향 차별 항목이 필요하다는 의견이 나와서 추가되었습니다.
API 시스템은 AWS API Gateway와 클라우드 기반 서버 AWS Lambda를 연결하는 방식으로 prototype을 개발했습니다.
추후에는 EC2, SageMaker 환경을 구축하여 실시간 혐오 발언 필터링이 가능하도록 계획 중에 있습니다.
본 API 시스템의 prototype은 https://bigwaveai.com/api/ 에서 체험하실 수 있습니다.
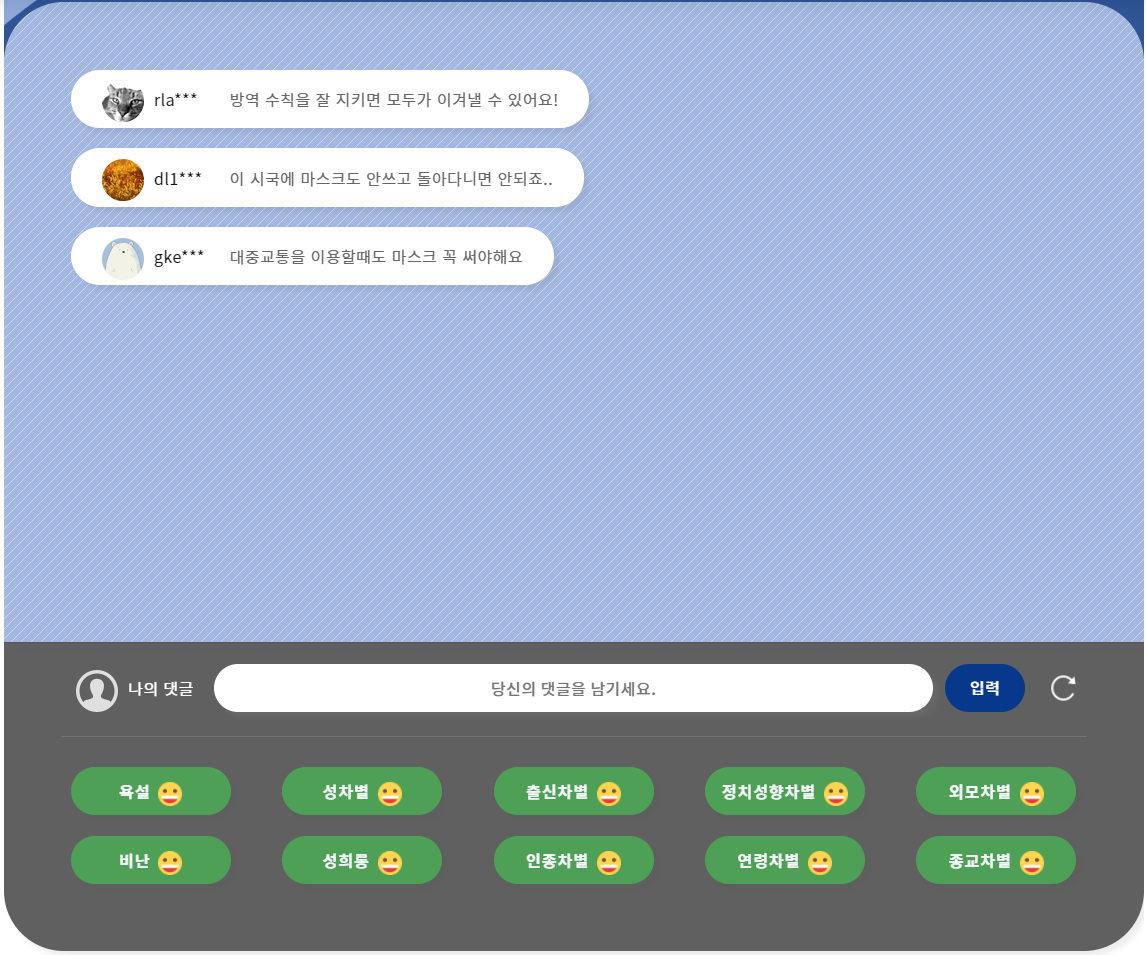
Know Comment API와 기존의 네이버 클린봇과 같은 댓글 필터링 시스템과의 차이점은 범용적인 차별 및 혐오 발언을 방지하기 위해 시스템을 구축한다는 점에 있습니다.
빅웨이브 팀은 인터넷 뉴스, SNS뿐만 아니라 인터넷 방송, 라이브 커머스 등과 같은 실시간 처리 서비스까지 할 수 있도록 모델링 및 시스템을 고도화하는 중입니다.
또한 악성 댓글의 세부 카테고리를 설정함으로써 해당 악성 댓글이 어떤 종류의 차별 및 혐오 발언인지 알 수 있습니다.
세부 카테고리 설정을 통해 다양한 범주의 차별적 표현에 대한 충분한 데이터를 기반으로 학습할 수 있습니다.
Know Comment API는 attention score를 기반으로 문장의 어떤 부분이 문제가 되는지 분석할 수 있습니다.
따라서 악성 댓글에 의한 사용자 제재 시 충분한 근거를 제시해줄 수 있습니다.
이제 어떤 딥러닝 기법을 활용하여 차별 및 혐오 발언을 효과적으로 탐지할 수 있는지 알아보겠습니다.
딥러닝 기법
지난 포스트에서는 Kim-CNN, Highway Network, OOV 처리를 활용한 악성 댓글 분류 모델을 소개해드렸습니다.
Know Comment API에 적용된 딥러닝 기법은 AMCNN을 기반으로 구축되었으며 기본적인 모델 아키텍처는 비슷합니다.
AMCNN(Attention-based Multichannel Convolutional Neural Network)은 Liu et al. (2020)의 연구에서 Kim-CNN의 고도화 버전으로 다른 텍스트 분류 기법과 비교하여 우수한 성능을 보입니다.
본 모델링 기법은 attention mechanism, BiLSTM(Bidirectional Long Short Term Memory), Kim-CNN, Highway Network 알고리즘이 결합된 형태입니다.
Kim-CNN과 Highway Network는 지난 포스트에서 설명드렸으므로 BiLSTM과 attention mechanism에 대해 설명드리겠습니다.
BiLSTM
BiLSTM은 RNN(Recurrent Neural Network) 기반의 LSTM 기법을 양방향 시퀀스로 학습하는 방식입니다.
RNN이란 데이터의 시퀀스 속성에 맞게 모델을 학습할 수 있는 기법입니다.
그런데 긴 시퀀스 정보를 가지는 데이터의 경우 순차적인 학습을 진행할 때 경사 소실(gradient vanishing)이라는 문제가 발생합니다.
이 경사 소실 문제를 해결하기 위해서 LSTM 기법이 등장했습니다.
LSTM 기법은 장기간 시퀀스 정보에 대해 gating unit 개념으로 학습 시 모델의 결과 값에 반영할 것인지 아닌지를 계산하여 처리합니다.
BiLSTM은 LSTM의 알고리즘을 양방향으로 학습하는 것으로, 과거의 데이터뿐만 아니라 미래의 시퀀스 데이터 또한 활용할 수 있기 때문에 seq2seq(시퀀스 데이터로 시퀀스 예측)에 유리합니다.
직관적으로도 앞의 문장만을 고려하는게 아니라 뒷 문장까지도 고려하는 것이 예측에 더 유리한 것은 당연할 것입니다.
BERT(Bidirectional Encoder Represenation Transformer) 이전 기계 번역과 같은 task에서 attention mechanism과 함께 사용되는 방식이 가장 우수한 성능을 나타냈습니다.

Attention Mechnism
attention mechanism이란 입력된 단어 벡터의 가중치를 부여해서 매 예측 시점마다 이를 반영하여 디코더의 출력 단어를 예측합니다.
Know Comment API에 사용된 attention 기법은 scalar attention, vector attention이 적용되었습니다.
scalar attention은 QKV(Query, Key, Value) 구조로 입력요소(단어)들 간의 연관성을 나타내는 행렬을 구하고 V에 해당하는 어텐션 가중치를 구하는 방식입니다.
즉, scalar attention은 입력 단어에 대한 벡터 값에 대한 어텐션 점수를 평가하여 중요도를 산정합니다.
입력 단어에 대한 어텐션 점수는 분류 예측 시 결과 값에 반영됩니다.
vector attention은 Bi-LSTM의 hiden state에 대한 attention score를 산출합니다.
vector attention score를 토대로 문장 분류 시 중요한 문맥에 집중(attention)할 수 있도록 합니다.

이제 위의 딥러닝 기법들을 가지고 구체적으로 모델링을 어떻게 구성했는지 순서에 맞춰서 설명드리겠습니다.
1. 데이터 전처리 후 Word2Vec 적용을 통해 임베딩 레이어에 입력
2. Bi-LSTM 학습과 함께 Scalar Attention과 Vector Attention을 산출하여 두개의 채널로 통합
3. 위의 3개의 알고리즘에서 산출된 결과 값들을 Multi-Channel features로 Convolutional Layers에 입력
4. Maxpooling 및 Concatenate로 결과 통합
5. Highway Network를 통해 과적합 방지
6. 최종 이진 분류
7. 클래스 당 분류 모델을 구축했으며 최종 예측 결과 값 통합
위의 과정을 도식화했을 때 다음과 같습니다.
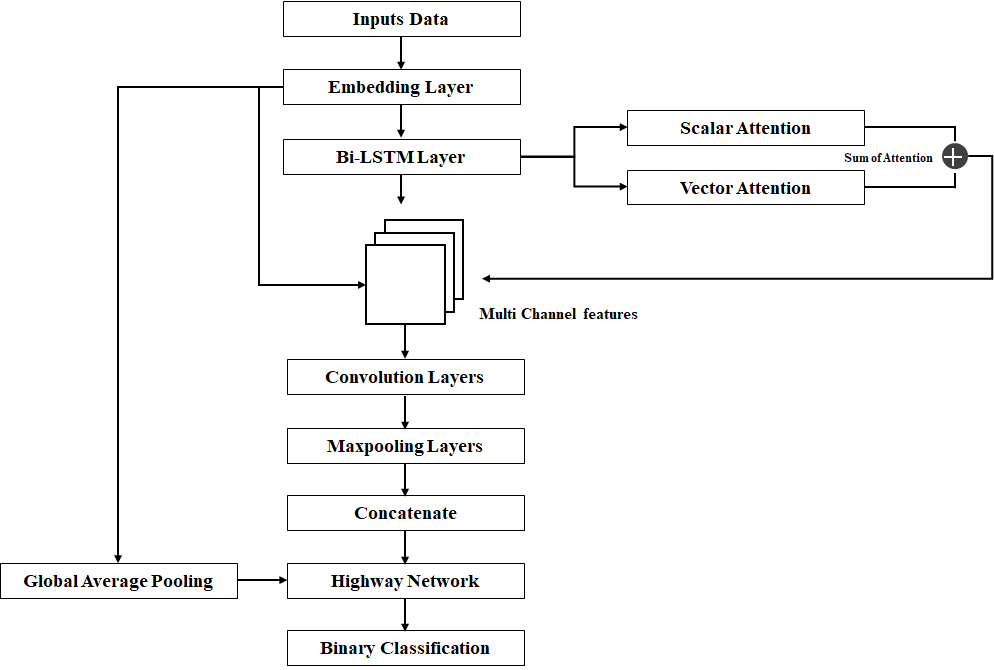
예측 결과
1차적으로 텍스트 데이터 약 13만개로 테스트한 결과 f1 score 기준 70.32%로 측정되었습니다.
기존 한국어 텍스트 분야의 SOTA(State of the Art)인 Ko-BERT와 비교했을 때 본 모델링의 결과가 더 우수하게 나타납니다.
특히 데이터의 개수가 상당히 적었던 종교 차별 및 인종 차별 부문에서 매우 큰 격차를 확인했습니다.
BERT의 경우 학습 과정이 오래걸리고 실시간 처리에 필요한 경량화에 어려운 부분이 있습니다.
실제적인 활용을 위해 CNN 기반 학습 모델을 개발했으며 결과적으로 Ko-BERT보다 더 우수한 성능을 나타냈습니다!

마무리
오늘은 저번 포스트의 악성 댓글 분류 모델을 고도화하여 범용적인 활용을 할 수 있는 차별 및 혐오 표현 탐지 시스템에 대해 알아봤습니다.
인터넷 뉴스 댓글뿐만 아니라 인터넷 방송, SNS, 온라인 동영상 플랫폼, 라이브 커머스 등 온라인 플랫폼 전체적으로 차별 및 혐오 표현이 큰 이슈가 되고 있는 상황입니다.
Know Comment API는 모두가 건전한 인터넷 문화를 향유할 수 있도록 어떠한 혐오 및 차별적인 발언도 놓치지 않고 탐지하는 것을 목표합니다.
이를 위해 데이터베이스, 모델링, API 등을 구축했으며 추가적인 소스를 활용하여 데이터베이스와 모델링을 고도화할 계획입니다.
특히 모델링의 경우 한국어의 특성에 맞게 자체 임베딩을 할 수 있는 기법을 연구 중입니다.
위의 포스트 내용은 논문으로도 정리되어 있으니 궁금하신 분들은 확인해보세요.
이원석, & 이현상. (2020). 딥러닝 기술을 활용한 차별 및 혐오 표현 탐지: 어텐션 기반 다중 채널 CNN 모델링. 한국정보통신학회논문지, 24(12), 1595-1603.
읽어주셔서 감사합니다!
다음 포스트 내용은 고객 이탈 방지 시스템을 개발하는 새로운 주제로 찾아뵙겠습니다.
'기술 블로그' 카테고리의 다른 글
| SOTA 알고리즘 리뷰 3 - TabNet (2) | 2021.06.25 |
|---|---|
| SOTA 알고리즘 리뷰 2 - Anomaly detection(PANDA, DEVNET, GAN,OCNN) (0) | 2021.06.18 |
| SOTA 알고리즘 리뷰 1 - Temporal Fusion Transformer (0) | 2021.03.27 |
| 고객 이탈 방지 시스템 (2020 AI Championship 2등) (5) | 2021.03.22 |
| 딥러닝 기술을 활용한 악성 댓글 분류 (2020 인공지능 온라인 경진대회 1등) (0) | 2021.03.09 |



