
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 빅데이터
- chatgpt 꿀팁
- 경진대회
- TabNet
- LLM 성능 개선
- 프롬프트
- 모델링
- LLM
- AI
- 프롬프트 엔지니어링
- ChatGPT 잘 쓰는 법
- GaN
- 프롬프트 잘 쓰는 법
- GPT3
- mergekit
- 거대언어모델
- 인공지능
- 악성댓글
- ChatGPT
- 강화학습
- 딥러닝
- SOTA
- IT
- GPT
- 비전러닝
- 컴퓨터 비전
- 프롬프트 페르소나
- 프롬프트 잘 쓰는법
- Transformer
- 머신러닝
- Today
- Total
빅웨이브에이아이 기술블로그
SOTA 알고리즘 리뷰 3 - TabNet 본문
안녕하세요! 빅웨이브에이아이의 박정환입니다.
지난 SOTA 알고리즘 포스팅 글은 이상치 탐지 분야의 PANDA, DEVNET, GAN, OCNN에 대해서 알아보았었는데요~
<혹시나 못보신 분들을 위한 링크 https://bigwaveai.tistory.com/6>
이번 시간에는 정형 데이터 분석 분야의 SOTA 알고리즘인 TabNet에 대해서 알아보도록 하겠습니다!
Key Idea
딥러닝이 발전의 발전을 거듭하고 있다고 해도, 이상하리만큼 정형 데이터쪽에서는 힘을 쓰지 못하고 있어왔습니다.
오히려, 정형 데이터는 기존 통계적 기법들이 우수한 성능을 보여주고 있었죠.
그러나, 딥러닝쪽에서도 어깨를 펼 새로운 모델이 등장했습니다 ! !
Google Cloud AI의 Sercan님과 Tomas님이 제안한 이 모델은 트리 룰에 기반하는 gradient boosting과 신경망 모델 구조의 장점을 모두 갖는 Tabnet을 제안했습니다.
Tabnet은 feature selection과 모델 해석이 가능한 고성능 딥러닝 기반 정형 데이터 분석 알고리즘 입니다.
모델링
1) Feature Selection
TabNet의 Feautre Selection은 Transformer 기반으로 Feature selection 후 정보를 통합합니다.
Sparse feature selection 방법론을 적용하며, 기능별로 하위 집합을 생성해 입력 처리를 거칩니다.
기존의 feature selection 방식은 모델에서 분리된 형태를 가지고 있었으나, TabNet은 단일 모델에서 같이 학습되는 구조를 가집니다.
2) DNN에서의 DT 활용
트리 기반 학습 기법인 LightGBM과 XGB는 기존 정형 데이터 분석 분야에서 SOTA를 차지하고 있었으나, 본 실험에서 딥러닝 기반 feature 표현 방식이 더 우수할 수 있는 것을 확인했습니다.
트리 룰에 기반하는 학습 방식은 feautre의 형질을 파악해 효율적인 학습을 할 수 있습니다.
이에, 기존 연구에서는 트리 기반 학습 기법과 DNN을 하이브리드하는 방식을 연구했었습니다.
하지만, TabNet에서는 새롭게 효율적인 학습을 위한 Transformer 기반 soft feature selection을 지원합니다.
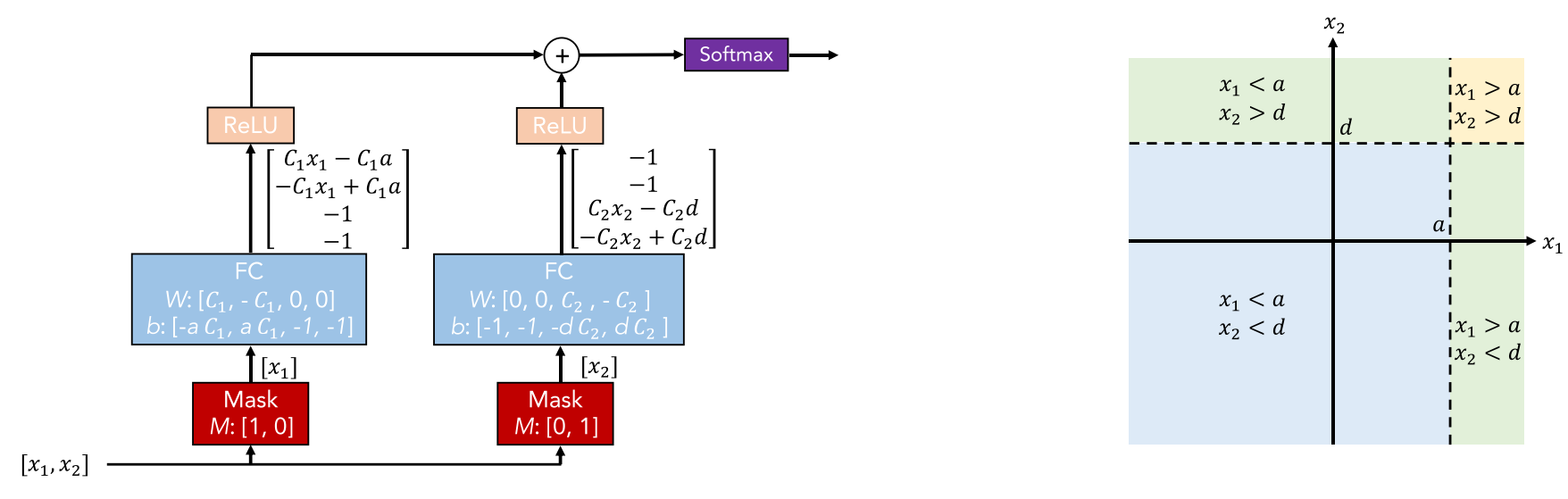
아래 그림은 DNN 구조에 DT가 결합된 형태입니다.
입력으로 다중 sparse masks를 활용해 feature selection을 합니다.
선정된 feature는 선형으로 변환되고 바이어스를 추가합니다.
ReLU는 region을 0으로 설정해 region selection을 진행합니다.
C1과 C2의 값이 커질수록 decision step이 sharp합니다.
3) 비지도 학습
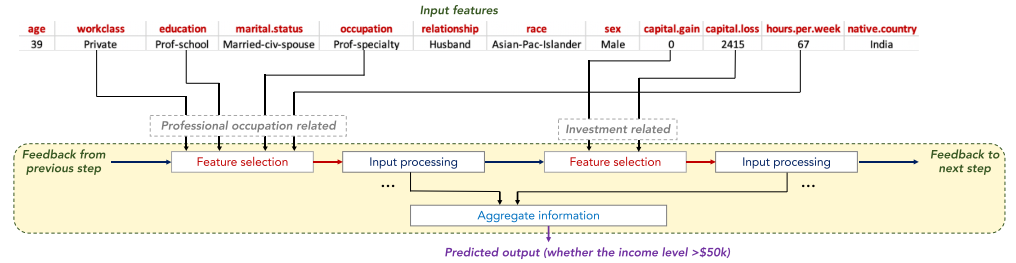
TabNet은 비지도 학습을 해, 소규모 데이터일 때도 효과적인 학습이 가능합니다.
입력 데이터에 대해서 랜덤으로 feature 값을 마스킹 후 비지도 학습을 합니다.
실제 데이터에서는 상호 의존적인 칼럼들이 존재하는데요, 예를 들어 직업을 보고 교육 수준을 예측하거나, 관계에서 성별을 추측하는 방식으로 모델이 학습됩니다.
위의 단계에서 칼럼간의 상호 의존성을 파악하여 decision step에 해당 정보를 반영합니다.
비지도 학습 모델의 인코더 구조는 지도 학습 모델로 전이되어 모델의 성능을 개선합니다.
비지도 학습 시 loss는 1이하가 되야 효과가 있습니다.
비지도 학습 모델과 분류 모델은 "꼭" 인코더 구조를 맞춰야 합니다! 그렇지 않으면 비지도 학습 모델이 먼저 실행되기 때문에 비지도 쪽으로 맞춰버리기 때문이죠.

Tabular Learning(정형 데이터)를 위한 TabNet
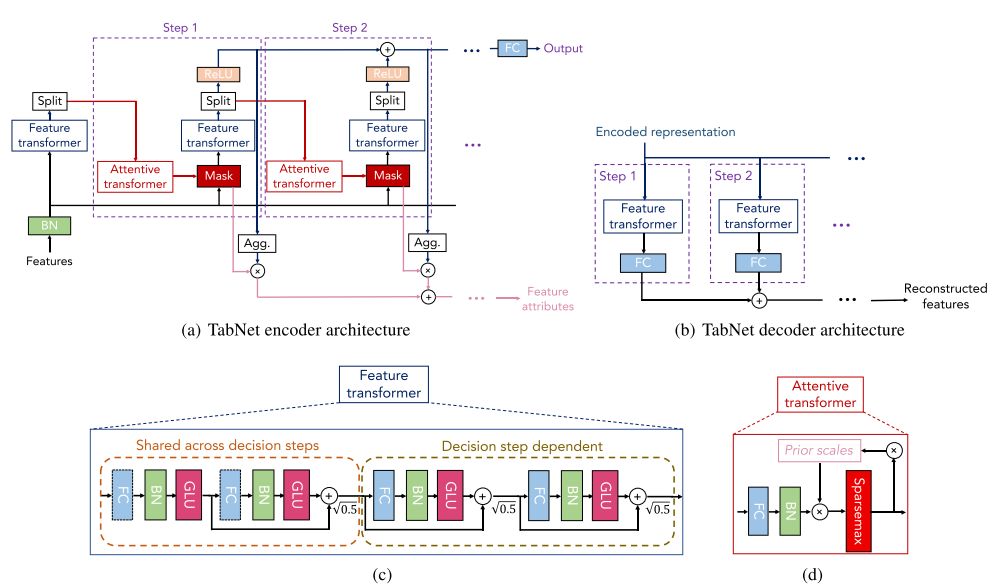
인코더는 각 Decison Step에 대해서 Feature Transformer, Attentive Transformer, Feature Mask로 구성됩니다.
Decision Step은 상호 의존적인 feature들을 선정하면서 최종적으로 feature 중요도 값을 평균하면서 목표값을 예측합니다.
디코더는 Feature transformer로 구성됩니다.
FC, BN, GLU를 단위로 구성하며, Shared Step에서는 모든 Step에서 공유되며 Dependent Step에서는 앞의 레이어에 의존적입니다.
Sparcemax를 통해 Feature의 중요도를 산출합니다. 행렬이 sparse하기 때문에 중요한 feature만 선정합니다.
이러한 구조는 DT에 비해 다음과 같은 이점을 가집니다.
1) 데이터에서 학습되는 sparse feature selection을 활용합니다.
2) 순차적 다층 아키텍처를 구성해서 정보를 통합합니다.
3) 선정된 feature의 비선형 처리를 통해 학습 능력을 향상합니다.
4) 더 높은 차원과 더 많은 단계로 앙상블 모형을 구현합니다.
5) 범주형 데이터를 입력 할 시, 임베딩 feature 매핑을 활용합니다.
마무리
이번 포스트에서는 정형 데이터 분석 분야에서 좋은 성능을 내고 있는 TabNet 모델에 대해서 설명드렸습니다!
TabNet은 여러 데이터셋에서 기존의 LightGBM과 XGB 모델들보다 우수한 성능을 보였습니다.
그리고 해석을 할 때, Feature Importance와 Feature들의 Global Importance를 제시했습니다.
하지만 빅웨이브 연구 팀에서 Tensorflow TabNet 및 Pytorch TabNet을 여러 데이터셋으로 실험한 결과 XGB 모델보다 성능이 잘 나오는 경우는 있었으나,
하이퍼 파라미터의 세밀한 조정이 필요하기 때문에 성능 향상에 시간이 필요합니다.
직접 번역한 것이다 보니 틀린 부분이나 어색한 부분이 있을지도 모르겠습니다.
지적 및 피드백은 감사한 마음으로 언제든 환영이니 댓글로 달아주시면 더 감사하겠습니다!
감사합니다 '_' !!
인용 자료
Arik, S. O., & Pfister, T. (2019). Tabnet: Attentive interpretable tabular learning. arXiv preprint arXiv:1908.07442.
'기술 블로그' 카테고리의 다른 글
| SOTA 알고리즘 리뷰 4 - ViT-G/14 (0) | 2021.07.26 |
|---|---|
| BentoML, 모델 서빙을 쉽고 빠르게 ! (0) | 2021.07.01 |
| SOTA 알고리즘 리뷰 2 - Anomaly detection(PANDA, DEVNET, GAN,OCNN) (0) | 2021.06.18 |
| SOTA 알고리즘 리뷰 1 - Temporal Fusion Transformer (0) | 2021.03.27 |
| 고객 이탈 방지 시스템 (2020 AI Championship 2등) (5) | 2021.03.22 |



