
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ChatGPT 잘 쓰는 법
- mergekit
- 경진대회
- 딥러닝
- GaN
- LLM
- TabNet
- 프롬프트
- GPT
- chatgpt 꿀팁
- 프롬프트 잘 쓰는 법
- GPT3
- 인공지능
- 모델링
- 비전러닝
- 프롬프트 페르소나
- 프롬프트 엔지니어링
- 거대언어모델
- SOTA
- 악성댓글
- 머신러닝
- 프롬프트 잘 쓰는법
- AI
- ChatGPT
- 컴퓨터 비전
- Transformer
- IT
- 빅데이터
- 강화학습
- LLM 성능 개선
- Today
- Total
빅웨이브에이아이 기술블로그
SOTA 알고리즘 리뷰 2 - Anomaly detection(PANDA, DEVNET, GAN,OCNN) 본문
안녕하세요! 빅웨이브에이아이의 박정환입니다.
지난 SOTA 알고리즘 포스팅 글은 시계열 분석 분야의 TFT(Temporal Fusion Transformer)에 대해서 알아보았었는데요~
<혹시나 못보신 분들을 위한 TFT 링크 https://bigwaveai.tistory.com/5>
이번 시간에는 이상치 탐지 분야의 SOTA 알고리즘인 PANDA, DEVNET, GAN, OCNN에 대해서 알아보도록 하겠습니다!
Key Idea
자 먼저, Anomaly detection이 무엇인지부터 알아보겠습니다! Anomaly detection이란, 주어진 sample에 대한 정상 여부를 판별하기 위한 알고리즘입니다.
예를 들어, 신용카드 사기 여부나, 침입 탐지, 의료 진단, 자율 자동차 주행 등과 같은 다양한 분야에서 사용될 수 있으며,
특히 제조업에서의 장비 및 불량 제품 탐지와 같은 중요한 문제를 해결할 수 있습니다.
다르게 말하면, 정상인지 비정상인지는 이진 분류(binary classification)로 생각할 수 있는데요!
기존 문제는 이 이진 분류 시 클래스 한 개의 데이터만 존재하는 Task가 있습니다.
그래서 이 경우 해결책으로, 다양한 범주의 데이터에서 이상치를 탐지하는 One Class Classification(OCC)을 사용합니다.
이 방법론의 핵심 아이디어는 정상 sample들을 둘러싸는 discriminative boundary를 설정하고, 이 boundary를 최대한 좁혀 boundary 밖에 있는 sample들을 모두 비정상으로 간주하는 것입니다.
이 OCC를 기점으로 한, 다음으로 소개될 SOTA 알고리즘들은 OCC를 위한 알고리즘이라 할 수 있습니다. 그 중, 가장 대표적인 것들이, 'PANDA', 'DEVNET', 'GAN' 입니다 !
PANDA
PANDA - Adapting Pretrained Features for Anomaly Detection, Reiss et al. (2020)의 핵심 기술에 대해서 설명해드리겠습니다.
첫 번째로, Initial Feature Extractor(초기 특성 추출)이 있습니다. PANDA는 ImageNet의 사전 학습 모델을 활용하여 이미지의 특성을 먼저 추출하는데요, ψ0(초기 특성 추출)은 사전 학습 모델의 손실 함수인 L에서 만들어집니다.
두 번째로, Feature Adaption(특성 적용)이 있습니다. ψ0(초기 특성 추출)은 사전 학습 모델의 손실 함수인 L에서 만들어진다고 말씀드렸었는데요! 사전 학습된 모델을 현재 데이터 셋에 맞게 미세 조정합니다.
Ψ는 미세 조정 후 특성 추출기를 나타냅니다.

세 번째로, Anomaly Scoring(이상 점수 부여)가 있습니다. PANDA는 앞선 과정을 거쳐, 이미지 Feature 추출 후, train set의 특성 ψ(x1), ψ(x2) … ψ(xN)을 추출합니다. 그리고, 이상치를 Scoring 할 수 있는 함수를 학습합니다.
Scoring 함수는 일반적인 데이터의 밀도(density)를 측정하고, 이와 분포가 다른 경우 높은 이상치 점수를 부여해, 탐지를 해냅니다.
DEVNET
다음은, DEVNET - Deep anomaly detection with deviation networks. (2019)의 핵심 기술에 관해서 설명해드리겠습니다.
첫 번째로, Anomaly Scoring Network(이상치 점수 부여 네트워크)가 있습니다. 함수 ϕ를 사용하여 주어진 입력 데이터 x에 각각 scalar 이상 점수를 산출합니다. 그리고, MLP(Multi Layer Perceptron) 기반입니다.
여기서 scalar라 함은, 하나의 수치만으로 완전히 표시되는 양을 뜻합니다.
두 번째로, Reference Score Generation이 있습니다. 이것은, 모델 학습을 위해 또 다른 scalar 점수를 생성하며, 샘플에 대한 이상치 점수 {r1,r2· · · , ri}의 평균으로 µR을 계산합니다.
그리고, Gaussian 분포 모델을 기반으로 이상치 탐지 방법론을 활용합니다. µR은 사전 확률 F로 결정되거나 모델에서 학습되는 수치를 말하는데, 사전 확률 F를 활용하는 것은 µR의 효율적인 계산과 해석 가능한 이상 점수가 필요한 경우 사용합니다.
* 여기서 잠깐 가우시안 분포란?
가우시안 분포는 정규 분포라고도 불리며, 자연 현상에서 나타나는 숫자를 확률 모형으로 나타낼 때 사용합니다.
다시 말해, 수집된 자료의 분포를 근사하는 데 자주 사용됩니다. 확률 밀도 함수로 나타내었을 때, 엎어진 종 모양을 가집니다.
정규 분포의 확률 밀도 함수를 나타내는 식은 아래와 같습니다. 그리고, 정규분포는 기댓값, 최빈값, 중앙값이 모두 같은 성질을 가지고 있습니다.
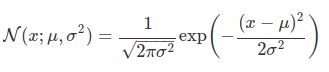
세 번째로, Deviation Loss입니다. ϕ (x), µR, σR은 최적화를 위해 편차 손실 함수 L에 입력합니다.
즉, 손실 함수 L{ϕ (x), µR, σR}은 이라 할 수 있겠습니다. σR은 {r1, r2, · · · , ri}의 표준 편차이며, 정규분포를 기준으로, 데이터 하나하나가 표준편차 상에 어떤 위치에 있는지 나타내는 Z-score를 기반으로 산출합니다!
수식으로 정리를 하자면, 아래와 같이 나옵니다.
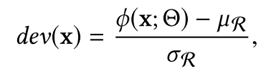


GAN
다음은, GAN -Based Anomaly Detection in Imbalance Problems. (2020)입니다.
GAN은 Generative Adversarial Network의 약자로, 생성자와 식별자가 서로 경쟁하면서 데이터를 만들어내는 모델을 의미합니다.
GAN은 여러 불균형 문제에 대한 다양한 해결책을 제시해, 문제를 해결합니다. 간략하게 한번 알아보도록 하겠습니다.
클래스 불균형의 문제를 K-means 군집화 기법을 활용한 샘플링으로 해결합니다. 군집화 후 각 그룹당 동일한 수의 이미지를 학습에 활용합니다.
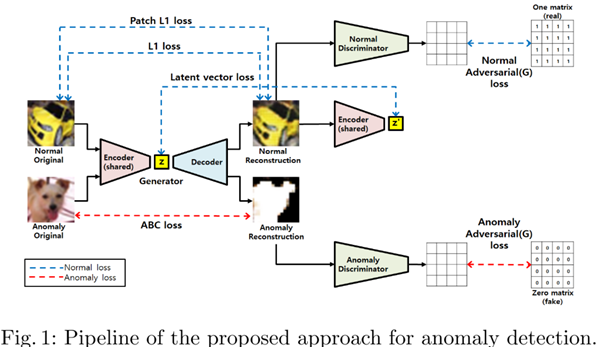
Loss Function Scale Imbalance (손실 함수 스케일 불균형 문제) 에서의 해결을 위해, Figure 1의 손실 함수 6개를 활용합니다.
손실 함수 6개의 weight를 계산하기 위해 Grid Search를 합니다.
Discriminator Distributional Bias (판별자 분포 편향 문제)에서는, 정상 데이터와 이상 데이터 모두에서 훈련할 때, 단일 판별자를 사용하면 정상 이미지만 잘 분류하도록 모델이 학습됩니다.
따라서, Figure 1과 같이 정상 이미지 판별자와 이미지 판별자를 분리하게 됩니다.
마지막으로, Size Imbalance between Object(defect) and Image(이상치 이미지 사이즈 불균형 문제)도 있습니다.
이미지 데이터 이상치의 경우 타겟 픽셀의 크기가 매우 작을 수도 있습니다.
때문에, 생성자(Generator)를 통해 이미지를 재구성해 픽셀의 크기를 재조정하는 방법으로 문제를 해결합니다.

OCNN
먼 길 오셨어요. 마지막으로, OCNN (One-Class Neural Networks)에 대해서 알아보겠습니다
OCNN은 OC-SVM의 손실 함수를 사용해서, 아키텍처를 설계합니다. OCNN은 이상 탐지를 위해 비지도 학습에서 얻은 기능을 활용하고 발전시킬 수 있어요 !
그럼, 정상 데이터와 이상 데이터 사이 Decision boundary가 매우 복잡한 데이터 셋에서 탐지를 할 수 있게 됩니다
선형 또는 시그모이드 활성화 함수를 갖는 하나의 hidden layer와 하나의 출력 노드가 있는 simple feed forward network를 설계합니다. 더 깊은 OCNN 아키텍처는 다음과 같이 정의할 수 있습니다.

여기서 weight는 은닉층에서 출력층으로 얻은 스칼라이고, v는 입력에서 은닉 단위로의 가중치 행렬입니다. 여기의 핵심은 OC-SVM의 내적 ⟨w, Φ (Xn :)⟩를 내적 ⟨w, g (VXn :)⟩로 대체하는 것입니다
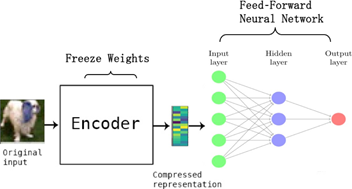
OCNN에서는 아래 (a)와 같이 오토인코더가 훈련됩니다! 그런 다음, 사전 훈련된 오토인코더의 인코더 계층이 복사되어 (b)에 나온 것처럼 하나의 hidden layer가 있는 feed-forward network에 입력으로 들어갑니다

정리하자면, 특정 데이터에 특화된 특징을 학습할 수 있다는 점에서, 기존에 제안된 Hybrid 방법론들과의 차이점이 있습니다.
기존 Hybrid 방법에서는 이미 학습된 딥 러닝 모델을 이용해 특징을 추출하기 때문에 추출된 특징이 이상치 탐지에 맞게 학습되었다고 할 수 없지만, OCNN에서는 학습된 오토인코더로 특징을 추출하고 다시 전이 학습(Transfer Learning)을 이용해 재학습시키기 때문에 특정 데이터의 이상치 탐지에 적합한 특징을 학습할 수 있습니다.
마무리
이번 포스트에서는 Anomaly Detection 분야에서 좋은 평가를 받고 있는 PANDA, GAN, DEVNet, OCNN 모델에 대해서 설명드렸습니다.
이미지 OOC Anomaly Detection은 중장비 탐지, 공정상 불량 탐지 CCTV 모니터링, 의료 의학 데이터 이상치 탐지 등으로 다양한 분야에서 범용적으로 활용 가능성이 높습니다.
PANDA와 GAN, OCNN은 이미지 기반이지만, DEVnet은 범용으로 실험 결과가 있는 것으로 나타났습니다.
직접 번역한 것이다 보니 틀린 부분이나 어색한 부분이 있을지도 모르겠습니다.
지적 및 피드백은 감사한 마음으로 언제든 환영이니 댓글로 달아주시면 더 감사하겠습니다!
감사합니다 '_' !!
인용 자료
Chalapathy, R., et al. (2018). "Anomaly detection using one-class neural networks." arXiv preprint arXiv:1802.06360.
Kim, J., et al. (2020). GAN-Based Anomaly Detection In Imbalance Problems. European Conference on Computer Vision, Springer.
Pang, G., et al. (2019). Deep anomaly detection with deviation networks. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining.
Reiss, T., et al. (2020). "PANDA--Adapting Pretrained Features for Anomaly Detection." arXiv preprint arXiv:2010.05903.
https://supermemi.tistory.com/72
https://hoya012.github.io/blog/anomaly-detection-overview-1/
https://blog.si-analytics.ai/18
'기술 블로그' 카테고리의 다른 글
| BentoML, 모델 서빙을 쉽고 빠르게 ! (0) | 2021.07.01 |
|---|---|
| SOTA 알고리즘 리뷰 3 - TabNet (2) | 2021.06.25 |
| SOTA 알고리즘 리뷰 1 - Temporal Fusion Transformer (0) | 2021.03.27 |
| 고객 이탈 방지 시스템 (2020 AI Championship 2등) (5) | 2021.03.22 |
| Know Comment API - 차별 및 혐오 표현 탐지 솔루션 (2) | 2021.03.19 |



